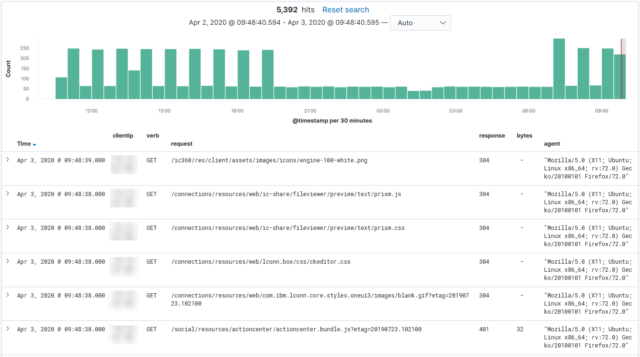
Der Grok-Parser von Logstash besitzt bereits eine Integration für die Combined Accesslogs des Apache2 Webservers. Es ist daher recht einfach möglich, diese Logs mittels Logstash zu parsen und an eine Elasticsearch-Datenbank zu übermitteln.
Combined Accesslog aktivieren
Apache bietet umfangreiche Anpassungsmöglichkeiten für das Logging. Unter anderem ist das sogenannte Combined Logformat gängig. Es protokolliert die Client-IP, den Benutzername bei Basic-Authentifizierung, Datum und Uhrzeit, Anfragemethode, den Referer (Quellseite), HTTP Antwortcode, Größe des HTTP-Bodys und den User-Agent des Clients. Diese Informationen sind für viele Anwendungsfälle ausreichend und daher ein guter Anfang, wenn man in einer zentralen ELK-Instanz protokollieren möchte. Darüber hinaus unterstützt Grok dieses Format von Haus aus.
Alternativ kann auch das Common Format genutzt werden. Es entspricht weitgehendst Combined, aber ohne den Referer und User-Agent. Im folgenden Beispiel kommt Combined zum Einsatz. Die vordefinierten Muster findet man im Pattern Github-Repo von Logstash.
Zunächst müssen wir das Format in der Apache-Konfiguration (meist httpd.conf) aktivieren. Im einfachsten Falle genügt dafür folgende Zeile:
CustomLog logs/access_log commonMöchte man Logrotate gleich mit einbinden und für jeden Tag eine neue Logdatei erstellen, ist dies wie folgt möglich:
CustomLog "|/opt/IBM/HTTPServer/bin/rotatelogs /opt/IBM/HTTPServer/logs/access_%Y_%m_%d.log 86400" commonHier wird als Beispiel der IBM HTTP Server für eine Connections-Installation genutzt. Da es sich um einen Fork von Apache handelt, kann dies auch in Apache verwendet werden. Gegebenenfalls weichen die Pfade ab, je nach verwendeter Distribution/Installationsart.
Parsen der Apache-Logs mit Logstash
Nun können wir die Logs mit Logstash zur Übermittlung an Elasticsearch parsen. Zunächst müssen wir die Logdateien als Quelle definieren:
input {
file {
path => "/opt/IBM/HTTPServer/logs/access_*.log"
type => "apache_access"
}
}Hier ist der Pfad entsprechend anzupassen. Ein Stern * kann als Wildcard genutzt werden. Dies ist beispielsweise bei der Verwendung von Logrotate nützlich.
Das Parsing der Logeinträge wird vom Filter übernommen:
filter {
if [path] =~ "access" {
mutate { replace => { type => "apache_access" } }
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
remove_field => [ "timestamp" ]
}
}
}Grok parst die Lognachricht mit dem vordefinierten Muster HTTPD_COMBINEDLOG. Wer sich für die Muster definiert, findet die Definition im oben verlinkten Logstash-Repo:
HTTPD_COMMONLOG %{IPORHOST:clientip} %{HTTPDUSER:ident} %{HTTPDUSER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
HTTPD_COMBINEDLOG %{HTTPD_COMMONLOG} %{QS:referrer} %{QS:agent}HTTPD_COMMONLOG ist das ebenfalls angesprochene, etwas kompaktere Logformat. Die Variablen werden nach dem Schema ${Datentyp:Variablenname} deklariert. %{NUMBER:response} steht beispielsweise für eine Zahl, die in der Variable response geparst und an Elasticsearch übermittelt wird. Der untere HTTPD_COMBINEDLOG Filter erweitert dies um den Referer und User-Agent des Clients. Für das reine Parsen der Apache-Logs benötigt man dies zwar nicht. Interessant wird es jedoch, wenn man ein exotischeres System an Logstash anbinden möchte, für das noch keine Muster existieren. Hier bietet aber auch die Doku weitere Informationen.
Schlussendlich müssen wir noch definieren, dass die geparsten Logs an einen Logstash-Server zu übermitteln sind:
output {
elasticsearch {
hosts => ["https://elasticsearch:443"]
# ssl_certificate_verification => false
index => "ihs"
}
stdout { codec => rubydebug }
}Wichtig ist, hier mindestens einen Elasticsearch-Host anzugeben und einen Index zu definieren. Der Index ermöglicht die spätere Zuordnung der Logs in Kibana (oder einer anderen Oberfläche). Die Variable ssl_certificate_verification kann für Tests in Unternehmensumgebung nützlich sein. Wird ein MITM-Proxy genutzt und das Zertifikat befindet sich noch nicht im vertrauenswürdigen Store, verweigert Logstash die Verbindung. Aus Sicherheitsgründen ist dies jedoch nur zu Testzwecken empfohlen. Wer dies hinter einem MITM-Proxy einsetzt, sollte zumindest dessen Stammzertifikat im Store hinterlegen. Dies ist zwar auch nicht optimal. Aber immer noch ein geringeres Risiko, als die Zertifikatsvalidierung komplett zu ignorieren.
Wird Logstash nun gestartet, sollten die ersten Anfragen in Elasticsearch aufgezeichnet werden. Durch den stdout-Block erhalten wir alle gesendeten Logeinträge auf der Konsole. Dies kann zum späteren Betrieb natürlich deaktiviert werden.