Elasticsearch ist einer der verbreitetsten Suchserver: Er ist schnell und bietet umfangreiche Möglichkeiten, um verschiedene Inhalte zu durchsuchen. Ein gängiger Anwendungsfall ist der ELK-Stack: Logstash sammelt hierbei die Logs von verschiedenen Anwendungen und speichert diese in Elasticsearch. Kibana ermöglicht das Durchsuchen sowie visuelle Aufbereiten der Daten in einem Web-Interface. Elasticsearch kann eben so für eigene Daten genutzt werden – beispielsweise um Anwendungen mit einer Suchfunktion zu versehen.
In diesem Artikel möchten wir uns auf ein simples Beispiel beschränken: Jeweils ein Container stellt Elasticsearch und Kibana bereit. Beispieldaten werden mit einem simplen Python-Skript eingefügt. Dies steht repräsentativ für eine Applikation.
Vorbereitung
Elasticsearch erfordert das Erhöhen des Kernel-Parameters vm.max_map_count. Hierzu folgenden Befehl als root ausführen:
sysctl -w vm.max_map_count=262144
Dies setzt den Parameter bis zum nächsten Neustart. Damit er dauerhaft erhalten bleibt, sollte er zusätzlich in /etc/sysctl.conf gesetzt werden.
Docker-Compose File erstellen
Zunächst erzeugen wir die zwei genannten Container:
version: '2.2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.8.3
mem_limit: 4G
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es-ul-test-data:/usr/share/elasticsearch/data
environment:
- bootstrap.memory_lock=true
- ES_JAVA_OPTS=-Xms512m -Xmx512m
- discovery.type=single-node
- http.port=9200
- http.cors.enabled=true
- http.cors.allow-origin=*
- http.cors.allow-headers=X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
- http.cors.allow-credentials=true
ports:
- 9200:9200
- 9300:9300
kibana:
image: docker.elastic.co/kibana/kibana:6.8.3
mem_limit: 2G
ports:
- 5601:5601
volumes:
es-ul-test-data:
Die Compose-Datei ist recht einfach gehalten. Nach dem Ausführen von docker-compose up -d dauert es einige Sekunden, bis ihr Kibana über http://localhost:5601 erreichen könnt.
Produktiv sollten mindestens http.cors.allow-origin auf die jeweilige Adresse des Frontends gesetzt sowie Kibana geschützt werden. Es empfiehlt sich jedoch, Elasticsearch nicht öffentlich erreichbar zu machen. Stattdessen soll nur über Wrapper (z.B. das Backend der Web-Applikation) darauf zugegriffen werden.
Index mit Beispieldaten erzeugen
Alle nachfolgenden Aktionen führen wir in der Konsole von Kibana aus: Links auf „Dev Tools“, dann „Konsole“. Es gibt aber diverse andere Methoden: Die Verwendung der Web-API mit einem Werkzeug wie curl, diverse Frameworks für nahezu alle gängigen Programmiersprachen (C#, Java, Python und weitere). Das manuelle Ausführen der Anfragen halte ich für den Einstieg am sinnvollsten, um ein Grundverständnis von Elasticsearch zu erlangen.
Zunächst erzeugen wir einen Index, den wir hier „test“ nennen:
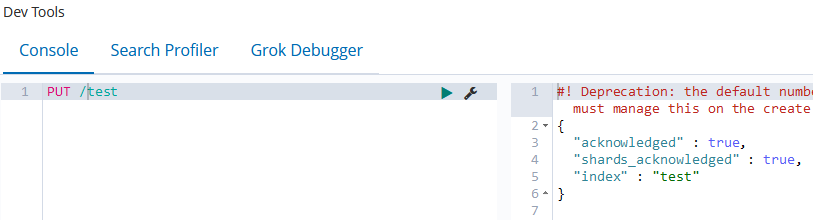
Die Warnung rechts kann für erste Tests ignoriert werden. Nun lassen sich Daten einfügen. Hierfür dienen JSON-Dokumente ohne Schema:
PUT /test/_doc/1
{
"title": "Erstes Dokument",
"author": "Testuser"
}
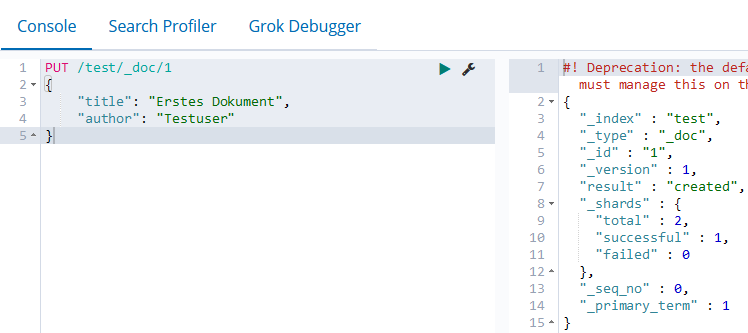
Nach diesem Schema können ein paar Testdokumente angelegt werden: Einfach die Id erhöhen und wahlweise die Daten etwas ändern.
PUT /test/_doc/2
{
"title": "Zweites Dokument",
"author": "DokTester"
}
Daten in Kibana anzeigen
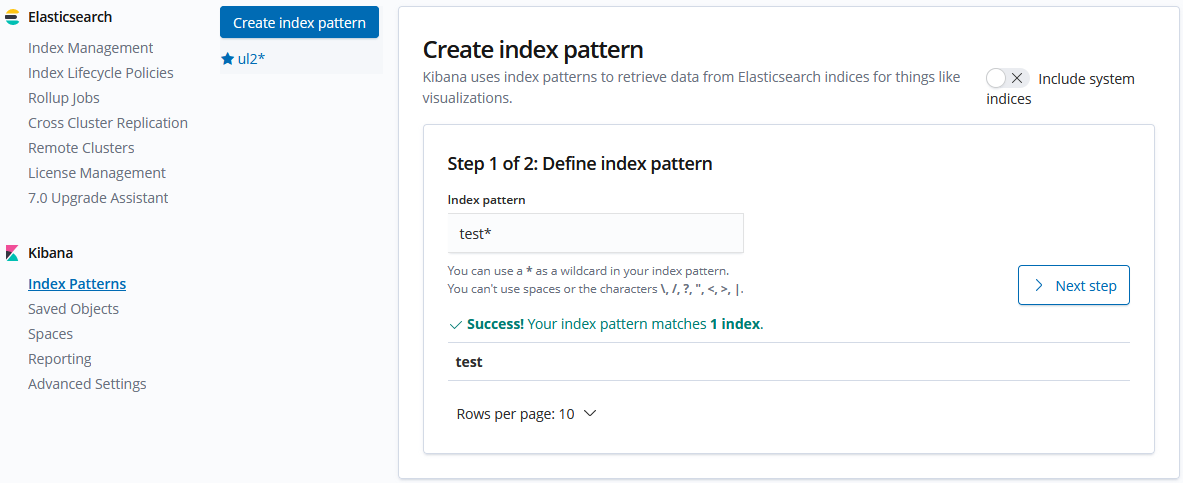
Zunächst fügen wir den Index hinzu: Management > Kibana Index Pattern > Create Index Pattern. In das Feld „Index pattern“ den Name des Index (hier „test“) eingeben und mit „Next Step“ sowie anschließend „Create Index Pattern“ bestätigen.
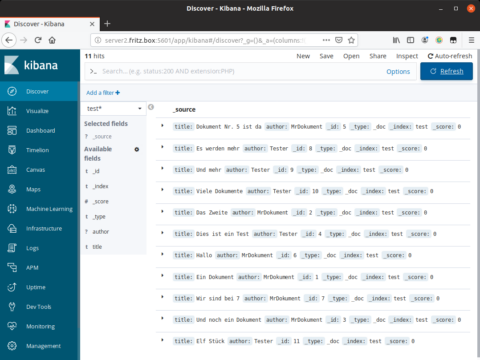
Nun in der Navigationsleiste links auf „Discover“ klicken und sicherstellen, dass der soeben angelegte Index „test*“ ausgewählt ist. Darunter sind die erstellten Test-Dokumente sichtbar:
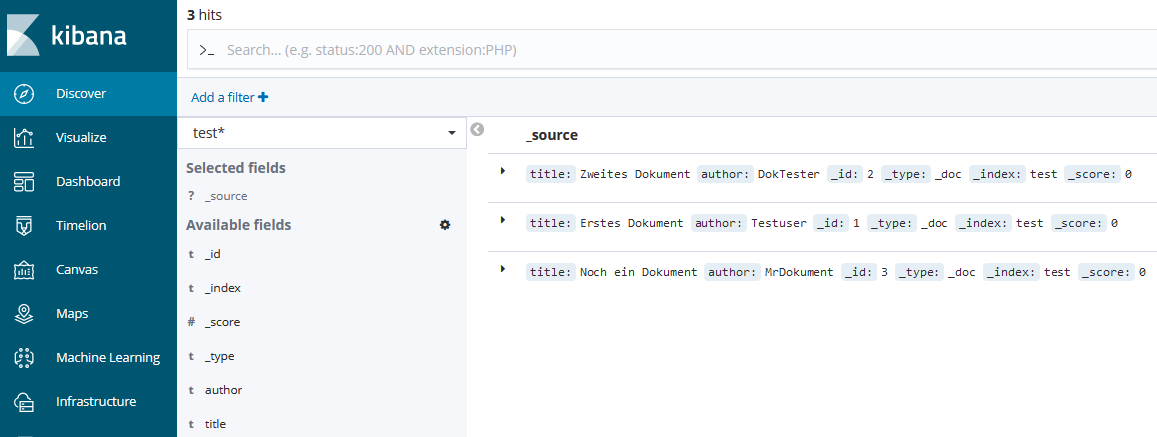
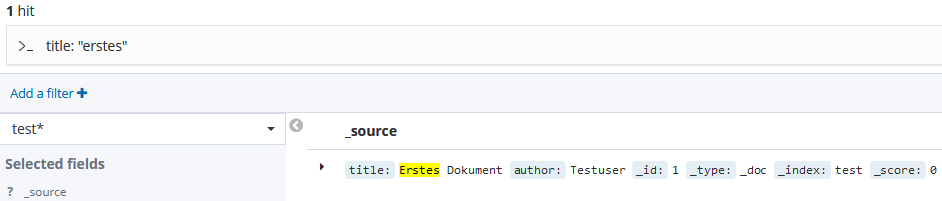
Via Klick lässt sich das Dokument ausklappen und mit entsprechenden Zeilenumbrüchen besser lesen (wichtig bei komplexeren Daten). Im Suchfeld oben können wir auf alle Eigenschaften filtern. Beispielsweise suchen wir mit
title: "Erstes"nach allen Dokumenten, deren Titel das Wort „Erstes“ beinhaltet:
Fazit: Mächtiges Werkzeug
Obwohl sowohl Elasticsearch als auch Kibana mächtige Werkzeuge sind, gelingt der Einstieg vergleichsweise schnell. Je nach Einsatzzweck kann man nun verschiedene Themen vertiefen, beispielsweise: Realisieren und Integrieren einer Suche, in Kibana Filter oder Diagramme zur Visualisierung erstellen usw. Letzteres ist vor allem für die Analyse von Logs nützlich. So könnte man sich ein Dashboard erstellen, dass beispielsweise in einem Diagramm alle HTTP-Statuscodes anzeigt und diese mit dem zeitlichen Auftreten verknüpft.
Diese Themen steigen jedoch deutlich Tiefer in die Thematik ein und würden den Rahmen dieses Artikels sprengen.