
Du hast noch nie mit Container-Technologie wie Docker gearbeitet? Dann ist dieser Artikel genau richtig für dich: Wir erklären dir die Vorteile, die auch auf Einplatinencomputer wie dem Raspberry Pi gegenüber einer klassischen Installation zu tragen kommen. Nach der Theorie geht es in die Praxis: Du lernst, wie du praktisch das richtige Image findest, um damit eine Anwendung als Docker-Container zu starten.
Was sind Docker-Container?
Klassischerweise installiert man alle Programme und deren Abhängigkeiten wie z.B. Bibliotheken direkt auf dem Raspberry Pi. Hauptsächlich in Form von APT-Paketen über die Paketverwaltung des Betriebssystems. Aber auch mit eigenen Paketmanagern verschiedener Programmiersprachen, wie z.B. Python PIP. So lange man nur eine Anwendung bzw. ein Projekt betreibt und dies nicht übermäßig groß ist, funktioniert dies zunächst meist auch. Spätestens wenn der Pi mehrere Anwendungszwecke abdecken soll, wird es komplexer: Die Abhängigkeiten wachsen und damit auch die Gefahr, dass diese sich in die Quere kommen. Vor allem wenn man etwas neues ausprobiert ist dies ärgerlich – möglicherweise zerschießt man sich damit andere, bislang stabil laufende Programme.
Hier kommen Container-Techniken wie z.B. Docker ins Spiel: Sie isolieren einen Prozess vom Host-System. Der Prozess erhält sein eigenes Dateisystem und eine eigenen Bibliotheken/Abhängigkeiten – ohne dabei den Host selbst oder andere Container zu beeinflussen. Dadurch können problemlos mehrere Versionen von Abhängigkeiten parallel genutzt werden, ohne sich in die Quere zu kommen.
Welche Vorteile bieten Containertechnologien wie Docker auf dem Raspberry Pi?
Im folgenden betrachten wir die Vorteile aus Sicht eines Raspberry Pi. Diese unterscheiden sich in so fern von x86 Servern und Workstations, dass z.B. Docker und andere Containertechnologien oft mit virtuellen Maschinen verglichen werden. Auf dem Raspberry Pi dagegen lassen sich VMs aufgrund der geringen Leistung kaum sinnvoll einsetzen. Hier installiert man seine Anwendungen direkt auf dem Pi, ggf. mit mehreren Pis. Auch ein paar andere Vorteile sind auf dem Pi nicht oder zumindest weniger relevant.
Reproduzierbarkeit & Flexibilität
Zwei klassische, per Hand konfigurierte Systeme sind selten identisch. Schon alleine weil das eine System vielleicht öfter geupgraded wurde als das andere, unterscheidet es sich minimal – möglicherweise treten dadurch eines Tages Probleme auf, die nicht reproduzierbar sind. In einem Docker-Image fügen wir aber nur die von uns explizit definierten Programme und Abhängigkeiten hinzu – es ist also klar definiert und reproduzierbar. Jeder Container, der auf Basis unseres Images erzeugt wird, verhält sich gleich. Wir können unsere Software also problemlos auf einem anderen Raspberry Pi übertragen, sie wird funktionieren und sich gleich verhalten. Außerdem lässt sich ein bestimmter Stand sehr einfach wiederherstellen.
Sogar über verschiedene Distributionen und teils Betriebssysteme hinweg. Wobei letzteres eher für den x86 Bereich relevant ist, beispielsweise wenn man unter Linux seine Docker-Container erstellt und jemand anders unter MacOS. Die Reproduzierbarkeit ist dagegen auch auf dem Pi nützlich.
Dokumentation sämtlicher Abhängigkeiten (+ leichte Versionierbarkeit)
Dadurch haben wir automatisch alles dokumentiert, was wir für die Anwendung sowie deren Konfiguration brauchen. Zumindest im Vergleich zur händischen Variante. Denn ohne Docker könnten wir natürlich auch Alternativen wie Ansible oder Shell-Skripte nutzen, um dies zu tun. Erfahrungsgemäß geschieht dies in der Praxis aber oft nicht, bei Docker machen wir das dagegen automatisch, quasi nebenbei – und haben zusätzliche Vorteile, da weder Ansible noch Shell-Skripte unsere Anwendungen ohne weiteres isolieren.
Legen wir unsere Konfigurationsdateien in eine Versionverwaltung wie Git, sind Änderungen nachvollziehbar. Sollte es zu Problemen kommen, schauen wir uns den Verlauf an, stellen eine ältere Version her. Nach dem Laden des Images bzw. vorherigem bauen entspricht die Umgebung dem jeweiligen älteren Stand. Lediglich um externe Programme müssen wir uns von Hand kümmern, etwa das Schema einer Datenbank, die im Zuge eines Anwendungsupdates verändert wurde.
Aktuelle Software, ohne ein instabiles System zu riskieren
Klassische Distributionen wie Debian und damit Raspbian aktualisieren die per APT bereitgestellten Pakete oft nur mit Verzögerung. Manche Pakete hinken den aktuellen stabilen Versionen der jeweiligen Programme sogar Jahre hinterher. Händisch neuere Pakete zu installieren bringt neue Probleme: Möglicherweise ist dies nicht mit den globalen Bibliotheken kompatibel, wodurch das System instabil werden kann. Installiert man händisch ein Paket an der Paketverwaltung vorbei, wird es zudem nicht automatisch aktualisiert – es drohen auf Dauer Sicherheits- und Kompatibilitätsprobleme.
Durch die Isolation erlaubt es uns Docker, einzelne Programme in deutlich aktuelleren Versionen zu installieren. Etwa ein neues PHP-Update. Dies bringt uns neue Funktionen, behebt bekannte Bugs und liefert teils auch sicherheitskritische Updates schneller aus.
Ein konkretes Beispiel ist der Webserver nginx: Die beim Verfassen des Artikels aktuellste stabile Version ist 1.20. In den Raspberry PI OS Paketquellen erhalten wir dagegen 1.14.2 aus dem Dezember 2018 – also etwa 2 3/4 Jahre alt.
Leichte Isolation zum Betrieb mehrerer Programme & Gefahrlose Tests
Auch Experimente sind dadurch leichter und ungefährlicher: Wir bauen ein Image (falls notwendig), erzeugen einen neuen Container und können leicht sowie gefahrlos etwas ausprobieren. Beispiel: PHP-Update von 7 auf 8. Den Tag auf 8 ändern, das Image bauen und testen. Dies kann gefahrlos in einer zweiten Instanz (neues Image + neuer Container) ausprobiert werden, ohne unser Hauptsystem oder andere Komponenten zu gefährden. Durch den problemlosen Parallelbetrieb lassen sich auch direkte Vergleiche anstellen. Beispielsweise können wir das Hauptsystem einer Anwendung vorerst auf PHP 7 laufen lassen, parallel dazu aber eine Testinstanz mit PHP8 starten – und etwa die Geschwindigkeit beider Installationen messen.
Werden mehrere Anwendungen betrieben, möchte man diese möglichst voneinander isolieren – so hat z.B. eine Sicherheitslücke darin nicht die Kompromittierung des gesamten Pis oder gar des Netzwerkes zur Folge. Klassisch ist dies zwar auch mit verschiedenen Techniken wie z.B. einem chroot-Jail möglich, jedoch komplexer und aufwändiger als mit Containern – die ja schon von Grund auf dafür konzipiert wurden, sich vor anderen Containern und dem Hostsystem zu isolieren. Für maximale Sicherheit sollte man jedoch auch hier Best Practices beachten, wie z.B. möglichst keine Prozesse dauerhaft als root laufen zu lassen.
Wie funktionieren Docker-Container?
Als Grundlage dient immer ein sogenanntes Image. Es besteht aus einem virtuellen Dateisystem, das aus mehreren Schichten aufgebaut wird. Man kann es sich ein wenig wie die Ebenen in Photoshop/Gimp vorstellen: Auf jeder Ebene befinden sich verschiedene Elemente. Übereinandergelegt ergeben sie ein komplettes Bild mit dem gewünschten Inhalt. Es gibt zwei Arten von Images.
Fertige Images (z.B. aus dem Docker-Hub)
Für viele Programme und Anwendungsfälle hat bereits jemand (im besten Falle der ursprüngliche Author/Entwickler) ein Image erstellt. Dies ist der schnellste und einfachste Weg, ich würde ihn daher bevorzugen, sofern möglich.
Selbst erstellte Images
Wir können entweder ein fertiges Image erweitern oder ein komplett eigenes Erstellen. Ersteres ist oft einfacher, schneller und nachhaltiger. Dies ist eine der größten Stärken von Docker: Benötigen wir beispielsweise PHP mit bestimmten Erweiterungen, müssen wir nicht von 0 auf ein Image mit der kompletten Installation/Konfiguration von PHP erstellen – sondern erweitern das fertige PHP-Image mit dem, was fehlt bzw. geändert werden soll. Vergleichbar mit Vererbung in der objektorientierten Programmierung: Statt eine Klasse zu kopieren und zu erweitern, erzeugen wir eine neue Klasse, die von der Basisklasse erbt und damit all deren Funktionen besitzt.
Was davon zum Einsatz kommt, hängt stark vom Anwendungszweck ab. Um Anwendungen von anderen zu Hosten, z.B. Nextcloud oder WordPress), kann man häufig fertige Images verwenden – zumindest wenn keine größeren Anpassungen gewünscht sind. Das selbst Erstellen wird spätestens dann notwendig, wenn eigene Anwendungen (z.B. Python-Skripte) dockerisiert werden sollen. Wobei man auch hier im Regelfall nicht von 0 auf anfangen muss, sondern im reichhaltigen Angebot des Docker-Hubs ein Image als Grundlage findet.
Ein wichtiger Unterschied zwischen fertigen und selbst erstellten Images: Fertige Images müssen lediglich heruntergeladen werden, anschließend sind sie sofort einsatzbereit. Ein selbst erstelltes Image muss dagegen einmalig (bis zu entsprechenden Änderungen) gebaut werden. Dies kostet je nach Inhalt und Leistung/Infrastruktur etwas Zeit, vor allem auf dem Raspberry Pi.
Wie nutze ich Docker-Container auf dem Raspberry Pi?
Du benötigst einen Raspberry Pi, am besten ein aktueller Pi 4. Ältere Modelle sind auch möglich, aber langsamer und aufgrund der geringeren Ressourcen (hauptsächlich des Arbeitsspeichers) nur eingeschränkt nutzbar – wenngleich es prinzipiell auch dort funktioniert. Wie du Docker auf dem Pi installierst, haben wir in folgendem Beitrag bereits erklärt: Docker einfach auf dem Raspberry Pi installieren (Anleitung für Einsteiger).
Wenn docker ps eine leere Tabelle wie im folgenden Beispiel anzeigt, ist dein Raspberry Pi richtig eingerichtet:
pi@ul-pi:~ $ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Beispielszenario: Starten eines Webservers (Nginx)
Als einfaches Beispiel für den Start möchten wir einen einfachen Webserver mit Docker starten. Ich entscheide mich für Nginx, da er aufgrund seiner Leichtgewichtigkeit für den Raspberry Pi gut geeignet ist. Prinzipiell könnten wir aber auch andere Alternativen wie Apache nehmen, dazu an anderer Stelle mehr.
Finden des passenden Basis-Images
Zuerst suchen wir im Docker-Hub nach einem passenden Image. Wichtig ist hierbei, links den Filter bei Architectures auf ARM zu setzen. Der Raspberry Pi nutzt nämlich eine andere Prozessorarchitektur, als die von den meisten Computern, Laptops und Servern gewohnte x86. Da diese nicht untereinander kompatibel sind, benötigen wir ARM-Kompatible Images. Ohne den Filter werden uns auch x86 Images angezeigt, die mit dem Pi nicht funktionieren.
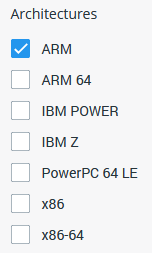
Die Architektur können wir auf der Konsole mit dem Befehl uname prüfen, der Schalter -m (für Machine) gibt uns die Prozessorarchitektur aus:
$ uname -m
armv7lAuf dem Pi wird dies in den meisten Fällen armv7l ausgeben, das entspricht der 32-Bit Architektur von ARM. Wie bei x86 gibt es auch hier 32 und 64 Bit. Im Gegensatz dazu ist 32 Bit bei den Pis durch ihren bislang geringen Hauptspeicher noch sehr verbreitet. Das Raspberry Pi OS in 64 Bit ist noch recht jung und macht nur auf den ebenfalls neuen Raspberry Pi 4 mit 8 GB Arbeitsspeicher wirklich Sinn. Dort erhalten wir aarch64 statt armv7l. Unser Pi hat nur 4 GB RAM (Limit für 32 Bit Plattformen) und läuft daher auf einem 32 Bit Raspberry Pi OS, weswegen wir in der Suche nur ARM als Filter ankreuzen.
Der erste Treffer ist ein offizielles Image. Es wurde also vom Entwickler/Eigentümer der jeweiligen Software (hier Nginx) selbst angefertigt und ist damit die vertrauenswürdigste Quelle. Unter der Beschreibung sehen wir mit der schlagwortähnlichen Ansicht, welche Architekturen unterstützt werden. Dieses Image kann also unter einem 64 Bit x86 Computer genau so genutzt werden wie auf dem Raspberry Pi mit ARM 32/64 Bit.
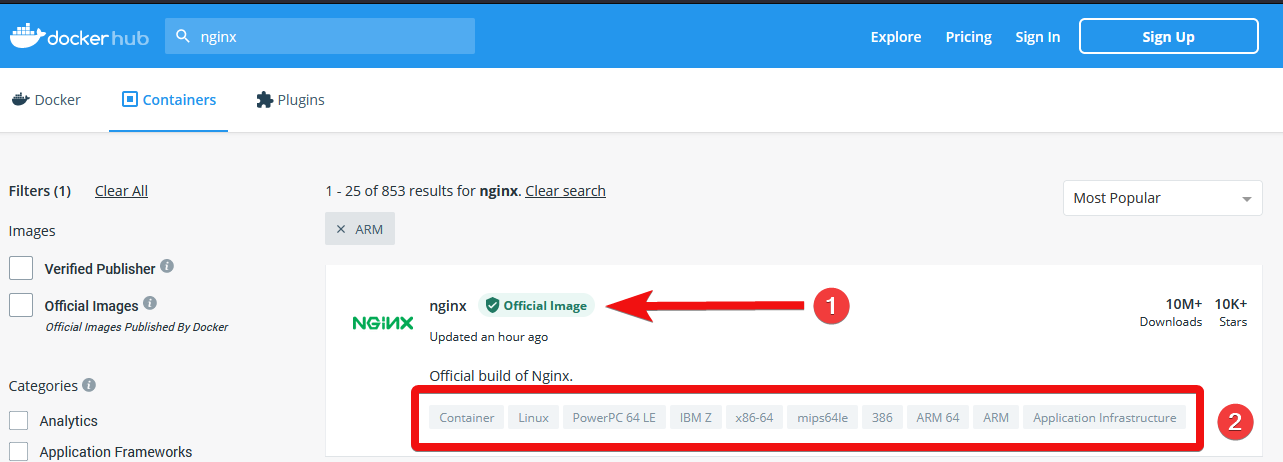
Weiter unten werden sich noch viele weitere Images finden. Das sind Community-Images – jeder kann Images erstellen und diese in den Docker-Hub hochladen. Grundsätzlich eine gute Sache. Allerdings sollte man – wie generell bei fremder Software – dem Ersteller Vertrauen. Vorsicht ist auch bei älteren Images geboten: Wenn diese seit längerem keine Aktualisierungen erhalten haben, gibt es wahrscheinlich offene Sicherheitslücken – eventuell auch Probleme mit der Software selbst, die in aktuelleren Versionen korrigiert wurden.
Brauche ich einen Tag?
Tags kann man am ehesten mit den Versionen eines Programmes vergleichen. Im Regelfall findest du in der Beschreibung eine Liste aller verfügbaren Tags. Diese ist am übersichtlichsten, sofern vorhanden. Alternativ kannst du auch oben auf den Reiter Tags klicken.
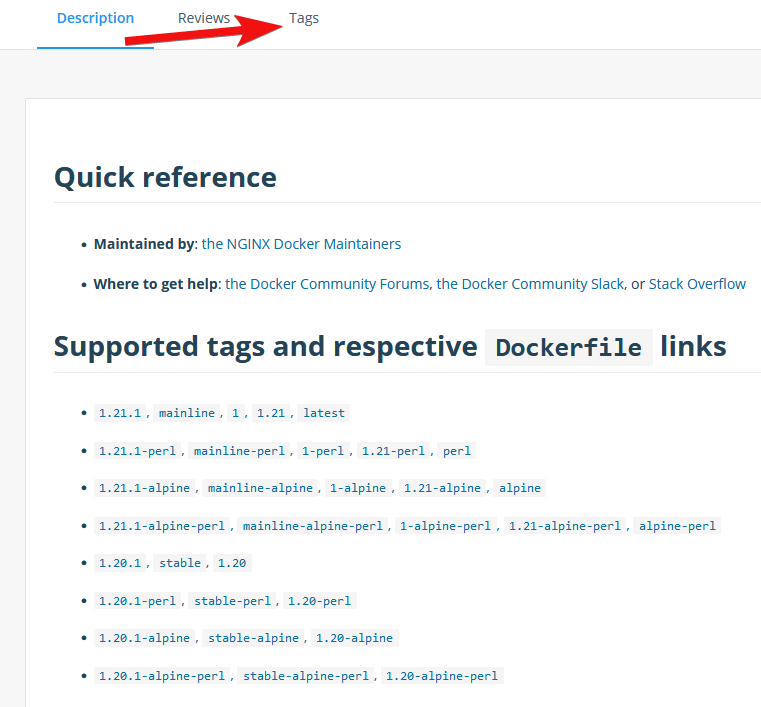
Oft haben wir mit den Tags jedoch nicht nur die Wahl zwischen der bestimmten Version eines Programms, sondern noch mehr:
- Gröbere Versionstags wie 1 oder 1.20 machen es uns einfacher, die aktuellsten Updates einzuspielen – ohne unerwartetes Verhalten zu erzeugen. Mit dem Tag 1.20 erhalten wir die derzeit aktuellste 1.20 Version. Hält sich der Entwickler an die semantische Versionierung, ist 1 oder 1.20 eine gute Wahl. Mit 1 erhalten wir nur abwärtskompatible Änderungen (z.B. neue Funktionalitäten, die vorhandene nicht beeinflussen) und mit 1.20 lediglich Fehlerkorrekturen, die ebenfalls abwärtskompatibel sind (ohne neue Funktionen). Allerdings erhalten wir diese Updates dadurch nicht automatisch, dies ist ein anderes Thema, das wir in einem getrennten Artikel behandeln.
- Verschiedene Basis-Images: Wie zuvor bereits erklärt, können Images aufeinander aufbauen. Nginx bietet uns hier verschiedene Basis-Images an: Standardmäßig ein minimales Debian, aber auch beispielsweise das deutlich schlankere Alpine.
- latest: Ein oft vorhandener Standard-Tag, der greift, wenn wir keinen spezifischen Tag angeben. Damit bekommen wir IMMER die aktuellste Version. Davon würde ich definitiv abraten, weil er die Reproduzierbarkeit deutlich einschränkt bzw. zerstört.
Für den Anfang brauchst du dir darüber keine all zu großen Gedanken machen und solltest lediglich den latest Tag meiden. Wir nutzen zur Vereinfachung die derzeit aktuellste, exakte Version 1.21 – damit ist der Vergleich zu einer händischen Installation am klarsten.
Starten eines Containers
Damit haben wir unser Image nginx:1.21 gefunden. Dies besteht im Folgenden immer aus einem Namen (nginx) und Tag (1.21). Mithilfe eines Images kann ein Container gestartet werden. Man kann sich Images ähnlich wie eine Schablone vorstellen. Es lassen sich also mehrere Container aus einem Image erstellen. Dafür kommt im einfachsten Falle der Befehl docker run zum Einsatz:
So einfach lässt sich ein Container starten. Ich empfehle, zusätzlich immer einen frei wählbaren Name anzugeben. Ansonsten generiert Docker zufällige Namen. Das erschwert die Zuordnung spätestens bei mehreren Containern.
Bei einem Webserver benötigen wir zudem mindestens eine Portweiterleitung. Ansonsten kann man den Webserver nicht erreichen, da Docker nicht nur das Dateisystem, sondern auch das Netzwerk des Containers isoliert. Dies geschieht mit dem Schalter -p 80:80. Dabei leiten wir Port 80 des Hosts (erste Angabe) auf Port 80 innerhalb des Containers.
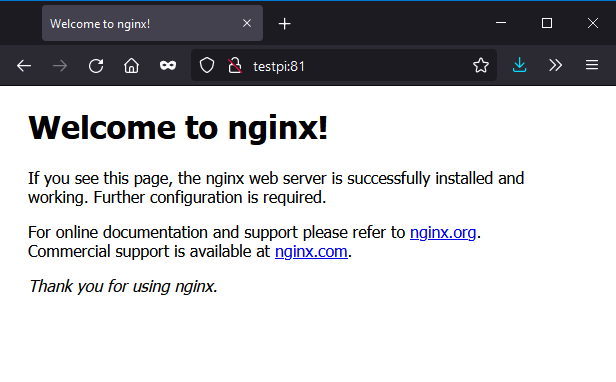
docker run --name webserver -p 80:80 nginx:1.21Der erste Start dauert länger, da zunächst das Image aus dem Docker-Hub geladen werden muss. Dies ist jedoch nur einmalig notwendig. Nach dem Start können wir den Webserver testen, in dem wir http:// gefolgt vom DNS-Hostname des Pi oder seine IP-Adresse im Browser eingeben. Am einfachsten ist der Hostname, der im Regelfall vom Router aufgelöst wird – also der Name nach pi@, hier etwa testpi. Dort sollte nun die Standard-Willkommensseite des Nginx erscheinen:
Ordner vom Host durch Volumes mit dem Container teilen
Wie kann ich nun eigene Seiten über den Nginx Webserver ausliefern, z.B. eine HTML Seite? Man könnte sich mit docker exec in den Container schalten und diese dort erstellen. Davon ist jedoch abzuraten: Container sind kurzlebig, sobald der Container neu erstellt wurde wären diese Daten verloren. Eine andere Möglichkeit wäre, ein eigenes Docker-Image zu auf Basis des Nginx zu erstellen. Dies ist ein wenig aufwändiger und wird daher Teil eines eigenen Artikels. An dieser Stelle schauen wir uns die einfachste und flexibelste Lösung für dieses Problem an: Volumes.
Ein Volume speichert persistente Daten, also jene die wir dauerhaft benötigen. Sie liegen außerhalb des Containers, sodass ein Volume auch dann bestehen bleibt, wenn wir den Container neu starten oder löschen. Es gibt verwaltete (Managed) Volumes und sogenannte Bind Mounts. Letztere sind am einfachsten und für unser einfaches Beispielszenario am besten geeignet: Damit stellen wir einen Ordnerpfad auf dem Host ganz einfach dem Container zur Verfügung – er wird im Container an der gewünschten Stelle gemountet. Hierzu gibt es den -v Schalter:
-v Hostpfad:ContainerpfadFür unseren Webserver erstellen wir einen Ordner, beispielsweise /home/pi/www und legen darin eine HTML-Seite namens index.html ab:
mkdir /home/pi/www
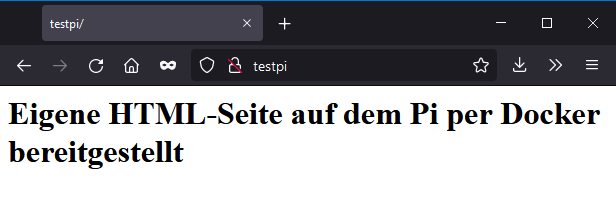
echo '<h1>Eigene HTML-Seite auf dem Pi per Docker bereitgestellt</h1>' > /home/pi/www/index.htmlDamit dieser Ordner über ein Bind Mount Volume dem Container zur Verfügung steht, müssen wir ihn neu erstellen. Zuvor den alten Container (der eben erstellt wurde) mit docker rm <Name> für remove löschen:
docker rm webserverUnd das Volume im docker run Befehl angeben. Das Ziel lautet /usr/share/nginx/html, da das Nginx-Image standardmäßig diesen Ordner als Webroot nutzt. Mit folgendem Befehl stellen wir den lokalen Ordner /home/pi/www im Container unter /usr/share/nginx/html zur Verfügung:
docker run --name webserver -p 80:80 -v /home/pi/www:/usr/share/nginx/html nginx:1.21Aktualisieren wir den Aufruf unseres Pi im Browser, erscheint statt der Nginx Standard-Seite nun der zuvor in die index.html geschriebene Text:
Container dauerhaft im Hintergrund laufen lassen
Möchten wir nun weitere Seiten hinzufügen (etwa eine test.html Seite), wird schnell ein Problem deutlich: Nach dem schließen mit STRG + C ist die Seite nicht mehr erreichbar – der Container wurde gestoppt. Dies liegt daran, dass der Container im Vordergrund gestartet wurde. Wie jedes andere Programm auch wird dies beendet, sobald wir entweder das Programm mit STRG + C beenden oder aber die SSH-Sitzung schließen. Klassischerweise würde man dies unter Linux mit einem Dienst (heutzutage hauptsächlich Systemd) lösen, der im Hintergrund läuft.
Unter Docker ist dies nicht notwendig: Hierfür gibt es den sogenannten detached Modus. Dies startet den Container im Hintergrund, ähnlich wie einen klassischen Dienst. Dafür ist lediglich der Parameter -d notwendig:
docker rm webserver
docker run -d --name webserver -p 80:80 -v /home/pi/www:/usr/share/nginx/html nginx:1.21Der Befehl gibt uns die Container-ID zurück. Eine Übersicht aller laufenden Container liefert docker ps. Die Spalte Container ID ist eine weniger sperrige Version der 64-Stelligen ID. Einfacher ist jedoch die Verwendung des Namens – ein Grund, warum ich oben empfohlen habe, stets sinnvolle und selbst festgelegte Namen zu vergeben.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1ab64f6afdf3 nginx:1.21 "/docker-entrypoint.…" 4 seconds ago Up 2 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp webserver
Konsolenausgabe (Logs, Fehler etc) des Containers einsehen
Durch den Detached-Modus sehen wir die Ausgabe des Containers nicht mehr – Im falle von Nginx die Zugriffs- und Fehlerprotokolle, die gerade beim Testen sinnvoll sein können. Anhand des Containernamens können wir die Logs mit
docker logs webserver -f–f folgt der Ausgabe, d.H. man sieht alle neuen Einträge live auf der Konsole – so wie bei docker run ohne -d Parameter. Möchte man nur die bisher vorhandenen Einträge ausgeben lassen, genügt docker logs webserver ohne -f.