
Künstliche Intelligenz (die technisch eher maschinellem Lernen entspricht) hat mit ChatGPT und DALL-E (2) die breite Masse erreicht. Letzteres ist der Bildgenerator von OpenAI, der aus Textbeschreibungen ein Bild erzeugen kann. Während die Ergebnisse durchaus interessant sind, handelt es sich um proprietäre (Cloud-) Technologie. Dem steht die Open Source Gemeinde mit Projekten wie Stable Diffussion entgegen: Selbst mit einem mehrere Jahre alten Gaming-PC ermöglicht es jedem zuhause selbst künstliche Bilder zu generieren. Spezielle Hardware ist nicht nötig, eine Grafikkarte mit möglichst viel Speicher reicht aus.
Was ist Stable Diffusion?
Ein in Python entwickelter Bildgenerator, der Bilder aus Textbeschreibungen (promts) generieren kann. Das Reparieren von beschädigten Bildern oder (z.B. ältere) in höhere Auflösungen hochrechnen. Das Projekt wurde vom Startup Stability AI in Zusammenarbeit mit verschiedenen Wissenschaftlern und gemeinnützigen Organisationen entwickelt. Die ersten Version erschien im August 2022. Im Vergleich zu proprietären Modellen wie DALL-E und Midjourney ist es quelloffen und jeder kann es selbst auf normaler PC-Hardware betreiben, ohne von Cloud-Diensten sowie deren Kosten/Einschränkungen abhängig zu sein.
Worin liegt der Unterschied zu kommerziellen Produkten von z.B. OpenAI?
Stability AI hat es damit geschafft umzusetzen, was bei OpenAI das ursprüngliche Ziel war: Deep learning (Maschinelles Lernen) Modelle frei der Allgemeinheit zur Verfügung zu stellen. OpenAI ist damit gescheitert, ein Mitgründer bezeichnet Anfang 2023 den offenen Ansatz sogar als Fehler – eine Kehrtwende um 180 Grad. Das Unternehmen hält sogar Informationen über die Funktionsweise oder Trainingsdaten von GPT-4 zurück. Wissenschaftler kritisieren dies, da die Eignung für ein Projekt sowie mögliche Risiken nicht abgeschätzt werden können. Fragwürdig wirkt zudem der Umstand, dass OpenAIs plötzlicher Sinneswandel nur wenige Wochen nach Microsofts Investitionen in Milliardenhöhe entstanden ist.
Auch der Abschluss eines Abonnements mit der damit einhergehenden Abhängigkeit entfällt, wie sie die kommerziellen Projekte zunehmend verlangen – zumindest für Teile der Funktionalitäten, etwa neuere Datenmodelle. Zensur findet ebenfalls nicht statt. Dieses Thema ist durchaus umstritten: Die Intention dahinter ist grundsätzlich nachvollziehbar. Jedoch schlägt sie in der Praxis gerne über die Stränge und ist nicht immer nachvollziehbar. Freie Software schränkt dies nicht ein. Es sollte jedoch auf der Hand liegen, dass die Generierung von eindeutig verbotenen Inhalten problematisch ist und besser unterlassen werden sollte.
Stable Diffusion (Web UI) auf dem eigenen PC: Das brauchst du
Zwar benötigt Stable Diffusion keine spezielle Hardware für zehntausende Euro, wie es bei den proprietären Plattformen der Fall ist. Da die Generierung von Bildern viel Rechenleistung kostet, wird dies auf dem wesentlich leistungsfähigeren Grafikprozessor (GPU) statt dem Prozessor (CPU) ausgeführt. Im Repository werden daher mindestens 10 GB Grafikspeicher verlangt. Es gibt Projekte, die den Speicherverbrauch optimiert haben: Stable Diffusion web UI verlangt nur 4 GB, mit entsprechenden Parametern sollen sogar 2 GB ausreichen. Darüber hinaus bietet es neben einer Weboberfläche weitere nützliche Funktionen.
Dazu müssen die proprietären Grafikkartentreiber geladen und installiert sein. Bei mir stammen diese von nVidia für eine ältere GTX 970. Wie dies geprüft und durchgeführt werden kann, variiert je nach Distribution. Manjaro bietet etwa eine grafische Oberfläche in den Einstellungen unter Manjaro-Einstellungen > Hardwarekonfiguration. Oben lässt sich der geeignetste Treiber automatisch erkennen und installieren. Die gleiche Funktion stellt das Kommandozeilenwerkzeug mhwd bereit.
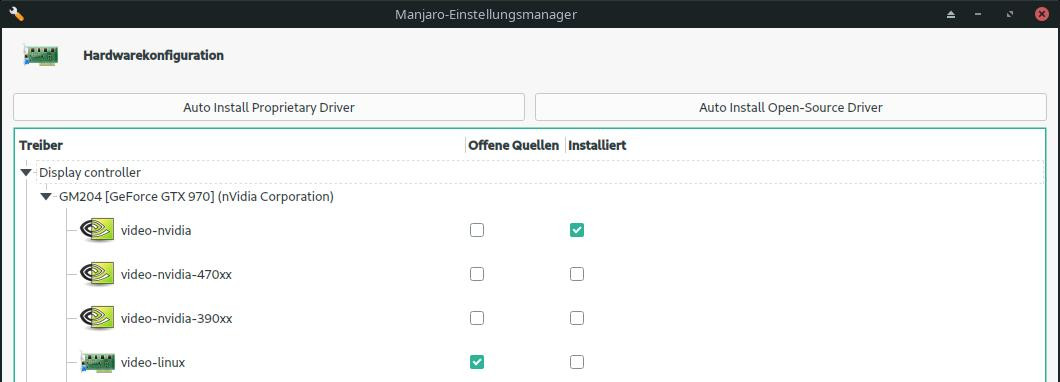
Unter Ubuntu findet man in den Einstellungen der Software- und Updateverwaltung einen Reiter für zusätzliche Treiber, in denen die verfügbaren aufgelistet werden. Per CLI listet ubuntu-drivers devices erkannte Geräte sowie verfügbare Software auf.
Darüber hinaus benötigt ihr Python3 und Git. Viele Distributionen enthalten es bereits, ansonsten ist es in der Regel über die gleichnamigen Pakete erhältlich. Das Python-Modul venv für virtuelle Umgebungen muss fast überall nachinstalliert werden.
# Ubuntu/Debian
sudo apt install python3-venv
# Manjaro
pamac install python-virtualenvWindows-Nutzer müssen alle Pakete händisch von den Webseiten der jeweiligen Anbieter herunterladen und manuell installieren. Zusätzlich ist dort Microsoft Visual C++ Redistributable erforderlich.
Installation
Klont das Repository in einen Ordner euerer Wahl:
git clone https://github.com/automatic1111/stable-diffusion-webui.gitDas Skript webui.sh nimmt uns einen Teil der Einrichtung ab, etwa zur virtuellen Python-Umgebung. Anschließend startet es den Webserver. Zuvor müssen wir hier noch Einstellungen vornehmen. Dafür gibt es die Datei webui-user.sh. Fügt dort eine Umgebungsvariable TORCH_COMMAND ein:
export TORCH_COMMAND="pip install torch torchvision torchaudio"Sie ist für PyTorch, eine Python-Bibliothek, um maschinelles Lernen auf die GPU (Grafikkarte) auszulagern. Die Pakete (und damit der Befehl) variieren je nach Umgebung. Auf der Webseite findet ihr ein Hilfswerkzeug, womit sich der korrekte Befehl zusammen klicken lässt:
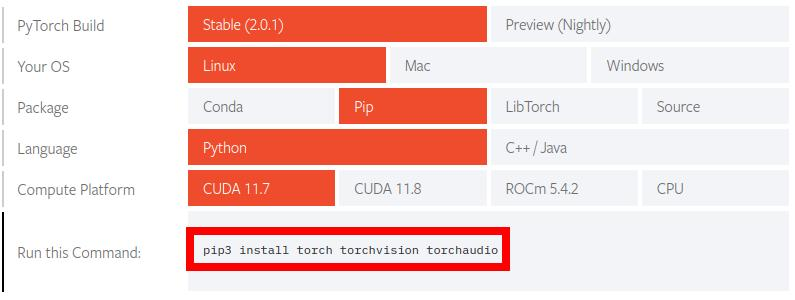
Anpassen müsst ihr ggf. Compute Platform. Hier wird zwischen ROC für AMD/ATI-Grafikchips und CUDA von nVidia unterschieden. Die CUDA-Version des Grafikkartentreibers kann über das im proprietären Paket enthaltene Kommandozeilenwerkzeug nvidia-smi ermittelt werden:
$ nvidia-smi | grep CUDA
| NVIDIA-SMI 530.41.03 Driver Version: 530.41.03 CUDA Version: 12.1 |Ist keine passende PyTorch-Version verfügbar wie in diesem Fall, müsst ihr selbst probieren. Ich habe es mit der aktuellsten CUDA 11.8 getestet und bin nach Problemen auf 11.7 gewechselt, damit läuft es stabil.
Verwendung
Theoretisch seid ihr damit nun bereit und könnt das webui.sh Skript ausführen. Der erste Start dauert einige Zeit, da mehrere Gigabyte an Daten für u.a. die Sprachmodelle heruntergeladen werden müssen. Torch neu zu installieren ist nur notwendig, wenn der Grafikkartentreiber eine größere Aktualisierung erhalten hat, oder die Karte gewechselt wurde. Zukünftige Starts laufen zügiger ab, hier prüft es lediglich auf Aktualisierungen. Sobald der Webserver läuft, erscheint die lokale Adresse in der Ausgabe:
[...]
Running on local URL: http://127.0.0.1:7860
[...]Die Web-Oberfläche erreichen wir somit durch Eingabe von http://127.0.0.1:7860 im Browser. Standardmäßig ist diese Adresse nur auf dem lokalen Computer erreichbar, auf dem das Skript gestartet wurde. Wer Stable Diffusion Web auch auf anderen Geräten im Heimnetzwerk nutzen möchte, fügt den Parameter –listen zur Variable COMMANDLINE_ARGS hinzu.
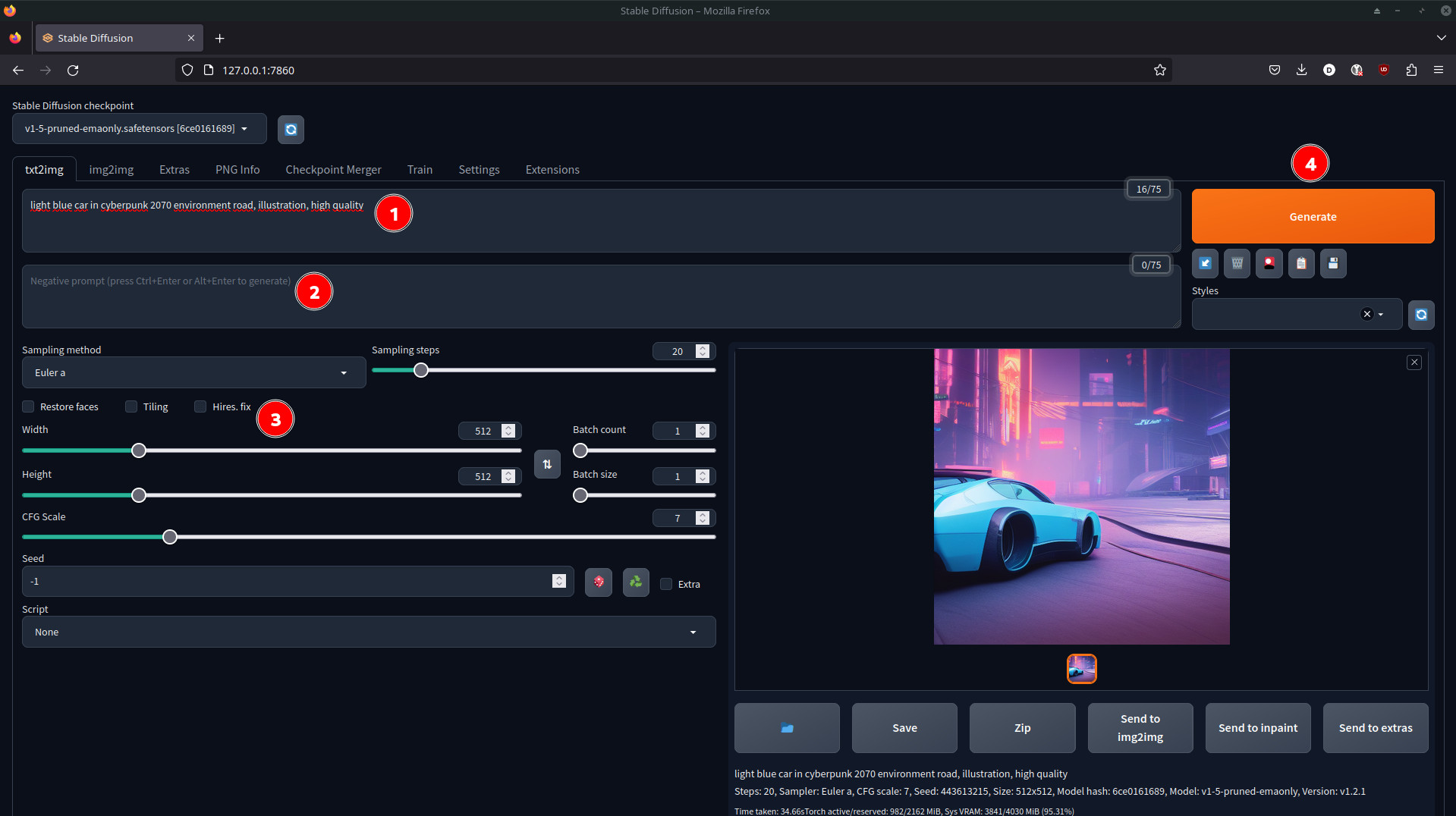
Die Web-Oberfläche besitzt im oberen Bereich mehrere Reiter für die verschiedenen Funktionen: Ein Bild mittels Text zu generieren ermöglicht txt2img, wobei Stable Diffusion Web mehr kann – etwa das Verbessern oder Bearbeiten vorhandener Bilder. Bleiben wir beim generieren von Bildern mittels Text, wird der sogenannte Promt in das Textfeld 1 eingegeben. Er beschreibt, was für ein Bild man erhalten möchte. Optional kann er durch einen Negativen Promt im Feld 2 darunter ergänzt werden: Dieser schließt aus, was auf keinen Fall auf dem Bild zu sehen sein soll.
Bereich 3 bietet Feineinstellungen, welche nicht für alle Bilder Relevanz besitzen. Außerdem kann dort die Größe sowie Anzahl der zu generierenden Bilder angepasst werden. Die vergleichsweise geringe Standard-Auflösung von 512×512 Pixeln ist jedoch nicht zufällig generiert: Je höher die Auflösung, um so mehr Ressourcen werden zur Generierung benötigt. Um sich Schlussendlich ein Bild erstellen zu lassen, klickt auf den Knopf 4 Generate.
Speichermangel? Drei Tipps, um Stable Diffusion Web auch auf Grafikkarten mit weniger Speicher nutzen zu können
Sollte die Generierung wegen zu wenig Speicher abbrechen (unter ~10 GB Grafikspeicher), lassen sich in der Variable COMMANDLINE_ARGS zusätzliche Parameter setzen. Mit --lowvram wird das Modell in mehrere Module aufgeteilt, die es nacheinander abarbeitet. Die benötigte Zeit zur Generierung verlangsamt sich dadurch, aber durch den geringeren Speicherbedarf funktioniert es dadurch auch mit weniger Speicher.
export COMMANDLINE_ARGS="--lowvram"Darüber hinaus gibt es noch –medvram für Karten mit mittlerem Speicher, also ungefähr mehr wie 4 GB, aber weniger als 10 GB: Damit wird die Parallelisierung weniger stark eingeschränkt, dafür ist der Speicherverbrauch höher – auf meiner 4 GB Karte brach die Generierung teilweise wegen Speichermangels ab:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 640.00 MiB (GPU 0; 3.93 GiB total capacity; 1.32 GiB already allocated; 605.94 MiB free; 2.02 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Ist der Grafikspeicher nicht ausreichend, bricht Torch mit einem OutOfMemory-Fehler ab
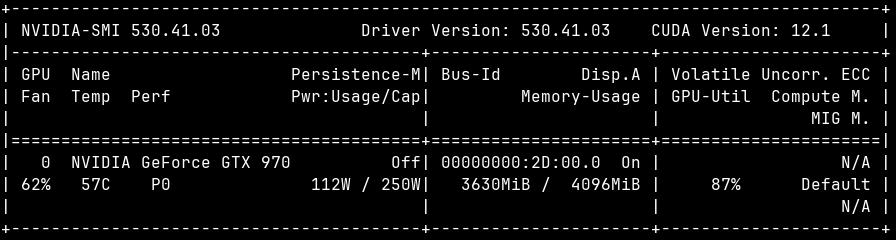
Eine weitere Optimierungsmöglichkeit steht ausschließlich für nVidia-Grafikkarten zur Verfügung: Xformers beschleunigt die Bilderstellung und reduziert den Speicherverbrauch, dafür sind die Ergebnisse nicht deterministisch. In meinen Tests wurden die Bilder etwa 3-4 Sekunden schneller erstellt, sowie knapp 500 MB weniger Grafikspeicher belegt. Ohne Xformers wird die GTX 970 während der Generierung stark ausgelastet:
Aktiviert wird es über das gleichnamige Befehlszeilenargument:
export COMMANDLINE_ARGS="--lowvram --xformers"Fazit
Stable Diffusion ist die erste umfangreich praktisch nutzbare quelloffene Software, um KI-Bilder auf normaler PC-Hardware generieren zu können. Selbst mit einer GeForce GTX 970 (4 GB Grafikspeicher) aus dem Jahre 2014 lassen sich beeindruckende Ergebnisse erzielen, die Wartezeit ist mit etwa 30 bis 40 Sekunden pro Bild erstaunlich moderat. Vor allem mit Blick auf OpenAI, welche die leistungsstarke (und teure) Azure-Cloud benötigen. Darüber hinaus macht Stable Diffusion Web die Technologie über eine Web-Oberfläche im Browser bedienbar und bündelt sie mit nützlichen Erweiterungen.
Für die Gesellschaft sind beide Projekte ein wichtiger Meilenstein, da diese Technologie tatsächlich jedem zugänglich ist. Stable Diffusion ist damit das geworden, was OpenAI sein wollte. In Anbetracht der rasanten Entwicklung wird es spannend zu sehen, wie die Projekte in ein paar Monaten oder Jahren nutzbar sein werden. Es dürfte eine Frage der Zeit sein, bis vergleichbares in 0815 Handy-Apps möglich ist. Schwieriger als die technischen Probleme wird der gesellschaftliche Umgang mit den neuen Chancen und Risiken sein: Während viele noch mit grundlegenden Themen wie Medienkompetenz an Schulen kämpfen, werden sie von ML/KI überrollt.