
Was ist „Web Scraping“?
„Scraping“ heißt kratzen oder abschürfen. Beim Web Scraping ließt man bestimmte Dateien einer Internetseite automatisiert aus, um sie weiterverwenden zu können. Beispielsweise um sie irgendwo anzuzeigen oder Analysen durchzuführen. Das wohl bekannteste Beispiel sind Bots von Google und anderen Suchmaschinen: Sie durchsuchen Internetseiten und speichern Informationen in ihrer Datenbank, um sie für die Suchergebnisse zu nutzen. Auch Preisvergleichsportale durchsuchen automatisiert die Shops zur Ermittlung der günstigsten Preise.
Wenn es keine Programmierschnittstelle (API) gibt, um die gewünschten Daten zu erhalten, ist Scraping oft die einzige Möglichkeit. Bei öffentlichen Daten ist es rechtlich legal, sofern das Urheberrecht beachtet wird. In anderen Fällen variiert die Legalität je nach Umständen.
Der Raspberry Pi eignet sich perfekt für Scraping, da er durch seinen geringen Stromverbrauch problemlos längere Zeit 24/7 laufen und regelmäßig Daten einsammeln kann. Grundsätzlich funktioniert es aber auch auf jedem X86 Server.
Was ist Selenium?
Selenium ist ein quelloffenes Framework, um Webseiten und Webanwendungen automatisiert zu testen. Dazu wird ein Browser ferngesteuert. Das kostet zwar etwas Ressourcen, hat aber einen großen Vorteil: CSS und vor allem JavaScript wird ausgeführt. Nützlich für Seiten, auf denen Inhalte dynamisch nachgeladen werden, etwa per Ajax oder WebSockets. Für Softwaretests ist das essenziell, bei Crawlern nützlich.
Das Beispiel-Szenario
Es gibt auf eBesucher eine Preisseite. Sie zeigt, wie viele Besuchertauschpunkte (BTP) ein Werbetreibender bezahlen muss, wenn er seine Seite für 15 Sekunden in der Surfbar angezeigt haben möchte.
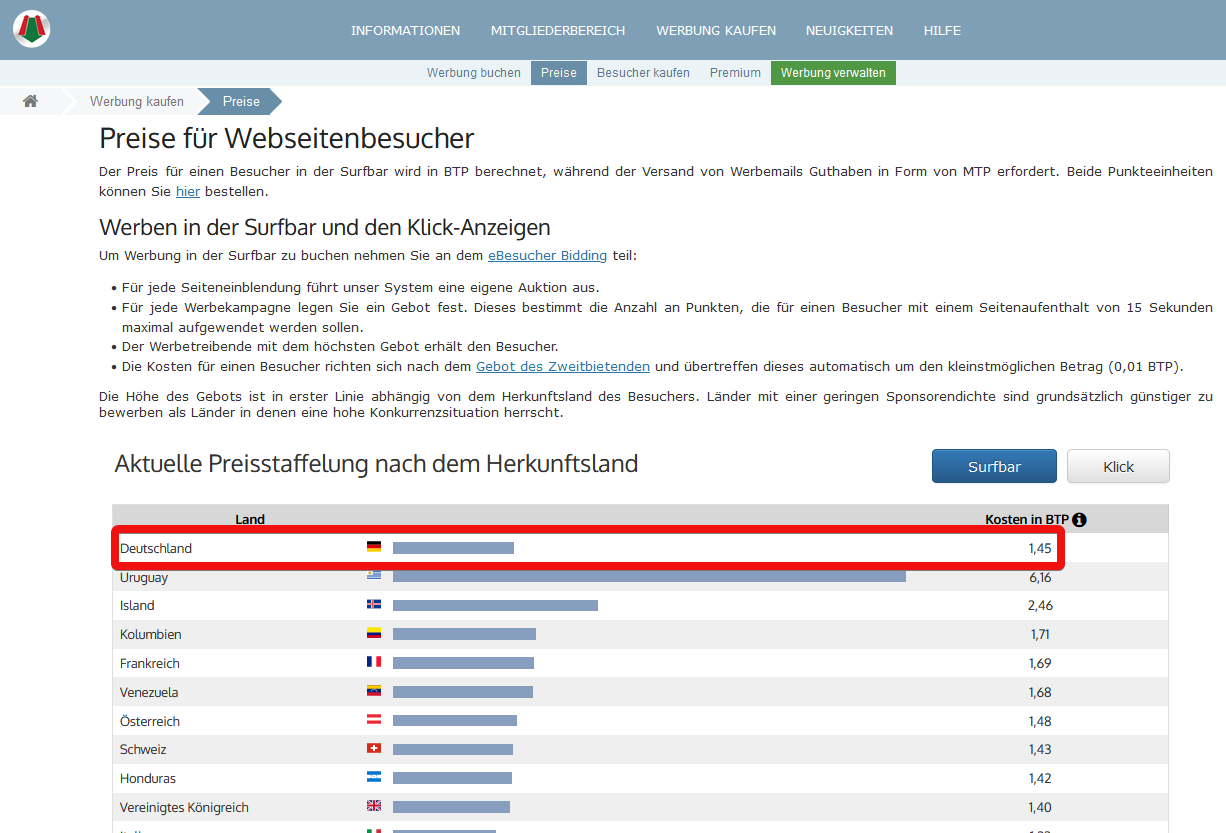
In diesem Beispiel soll also ausgelesen werden, dass eine Einblendung in Deutschland derzeit 1,45 BTP kostet. Dieser Preis kann sich ändern, in welchen Abständen ist nicht bekannt. Unter anderem das können wir mit unserem Scraping versuchen herauszufinden.
Vornweg: Diese Seite ist recht simpel aufgebaut und ließ sich relativ einfach mit händischen HTTP-Anfragen auslesen – das ist in der Ausführung effizienter, aber weniger vielseitig bzw. bei komplexeren Internetseiten deutlich aufwändiger/fehleranfälliger zu implementieren als Selenium. Gerade weil diese Seite nicht übermäßig komplex ist, eignet sie sich gut zur ersten Demonstration. So kann ein Einsteiger die Funktion verstehen, statt gleich zu Beginn mit der Komplexität von Sonderfällen erschlagen zu werden.
Was brauche ich?
Wir nutzen die verbreitete Skriptsprache Python in Version 3.7 oder höher. Selenium wurde aber mittlerweile in nahezu alle gängigen Sprachen portiert, dort kann es mit einigen Anpassungen ebenfalls verwendet werden. Python3 sollte unter dem Raspberry Pi OS bereits installiert sein:
$ python3 --version
Python 3.9.2
Der Python-Paketmanger Pip ist standardmäßig nicht vorhanden, daher installieren wir ihn zunächst:
sudo apt install python3-pip
Da wir Pip-Abhängigkeiten benötigen, empfehle ich eine virtuelle Python-Umgebung. Anschließend mit pip das Selenium-Paket installieren, dies integriert Selenium in Python.
$ virtualenv ebesucher-scraper
$ cd ebesucher-scraper
$ source bin/activate
$ pip3 install selenium
Nun benötigen wir einen WebDriver. Dies ist die Selenium-Implementierung für einen einzelnen Browser, der ferngesteuert wird. Für Tests gibt es auch andere Varianten, etwa Grid zur parallen ausführung mehrere Tests. Es gibt verschiedene WebDriver-Implementierungen, da man Webseiten ja in der Regel nicht nur in einem Browser testet.
Normal nutze ich hierfür den quelloffenen, freien Browser Firefox. Leider gibt es für den notwendigen Geckodriver für die ARM-Architektur des Raspberry Pi weder in der Paketverwaltung, noch zum Download. Daher weichen wir auf Chromium auf.
sudo apt install chromium-driver
Hinweis: Die Pakete sind recht groß und installiert den Chromium-Webbrowser als Abhängigkeit, sofern noch nicht vorhanden. Insgesamt werden ca. 137 MB heruntergeladen und 520 MB auf euere Speicherkarte entpackt.
Grundgerüst und ein erster Test
Beginnen wir mit einem einfachen Beispiel: Erzeugen eines Chrome WebDriver-Objektes, dass wir Headless aufrufen. Dadurch seht ihr das Browserfenster nicht. Zur Fehlersuche kann es nützlich sein, dies auszukommentieren, sodass wir sehen, was Selenium tut. Funktioniert aber nur, wenn ihr entweder eine grafische Oberfläche nutzt, oder aber mittels X-Forwarding die Fenster lokal öffnet.
Unser Chromium-Browser soll die Startseite Qwant öffnen und uns dem Titel ausgeben. Den seht ihr beim Surfen normal in der Titelleiste des Browsers bzw. teile davon in der Registerkarte.

Legt für folgenden Code ein Python-Skript an, ich nenn es crawler.py und öffnet dies mit einem Texteditor.
from selenium import webdriver
from selenium.webdriver.common.by import By
# Verhindert, dass das Browserfenster geoffnet wird (per SSH ohne GUI/X-Forwarding zwingend notwendig)
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument("headless")
driver = webdriver.Chrome(options=chromeOptions)
driver.get('https://qwant.com')
print(driver.title)
driver.quit()
Anschließend das Skript ausführen. Es sollte der entsprechende Titel ausgegeben werden:
$ python3 scrape.py
Qwant - The search engine that respects your privacy
Hier auf Englisch, weil das die Standard-Sprache von Chromium ist. Dies lesen manche Internetseiten aus und passen ihre Sprache entsprechend an. In Selenium könnte man die Sprache auf Deutsch ändern, das ist hier aber nicht relevant.
Auslesen des Deutschen BTP-Preises mit Selenium
Nun geht es mit eBesucher weiter. Zunächst ändern wir die Adresse, die Selenium aufrufen soll:
# Statt vorher: driver.get('https://qwant.com')
driver.get('https://www.ebesucher.de/werbung/preise')
Wird das Skript erneut mit dem Python-Befehl wie zuvor gezeigt gestartet, sollten wir den Seitentitel von eBesucher sehen können:
$ python scrape.py
Preise für Webseitenbesucher | Preisrechner | eBesucher.de
Nun hilft der Seitentitel fürs Auslesen von Daten nicht weiter, das war nur als Test zum aufwärmen gedacht. Um Daten auszulesen, müssen wir uns zunächst mit der HTML-Struktur der Seite beschäftigen. Am besten fängt man mit dem Element an, dass man auslesen möchte: Im Firefox dort einen Rechtsklick auf das gewünschte Element (hier der BTP Kurs, aktuell „1,45“) und dann auf Untersuchen im Kontextmenü.

Die blaue Zeile ist das Element, auf das wir den Rechtsklick durchgeführt haben. Mit dem Pfeil links kann man das Element aufklappen. Es ist also ein <td> Element (Feld einer Tabelle), in dem der Wert steht.
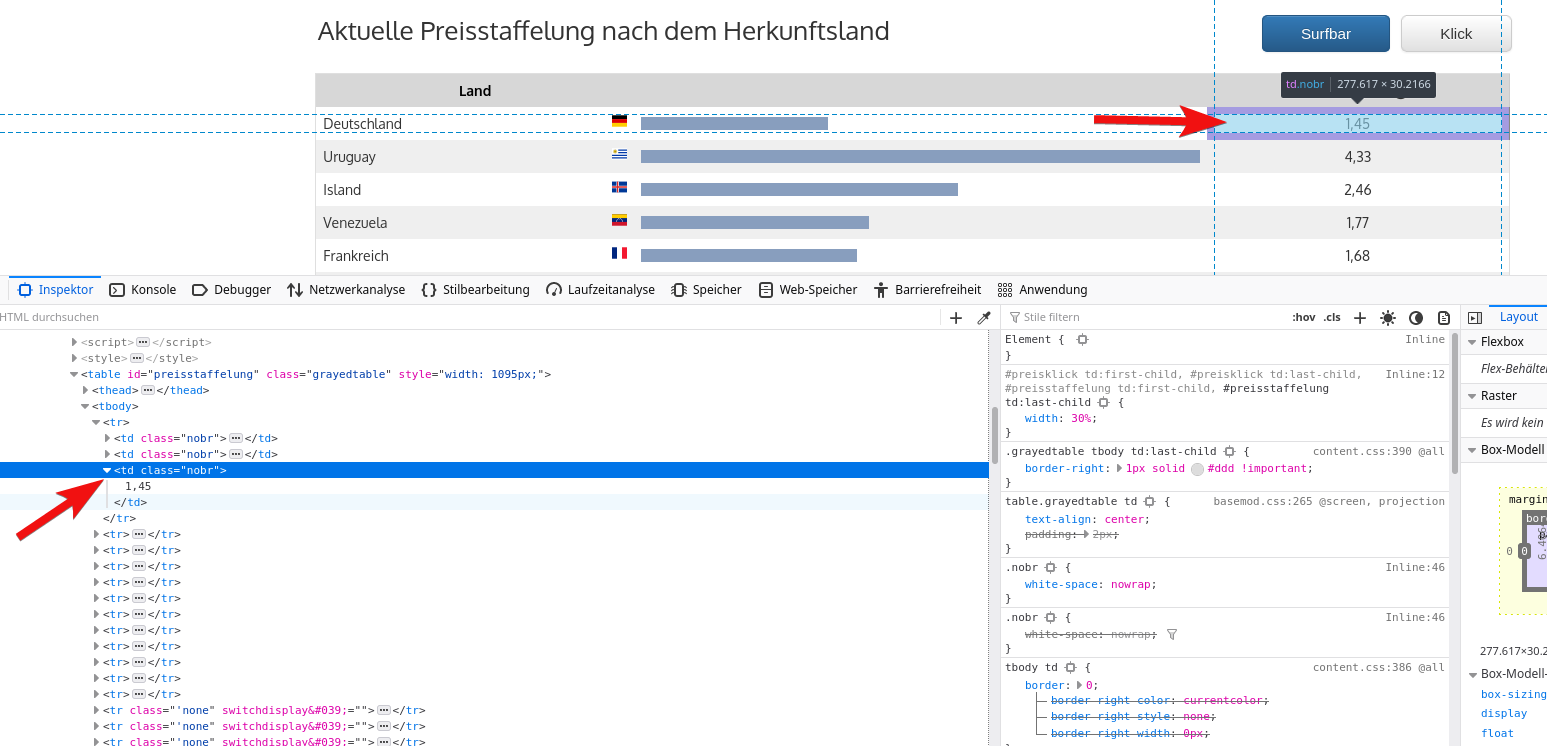
Interessant ist vor allem der linke Bereich mit der HTML-Struktur. Die müssen wir analysieren und einen Selektor finden, um das gewünschte Element zu finden. Hilfreich sind dabei vor allem Ids, damit lässt sich ein Element am einfachsten identifizieren. Alternativ gibt es Klassen, manchmal muss man auch auf die Verschachtelung der Elemente gehen.
In diesem Falle funktioniert leider alles nicht: Das <td> Element hat nur eine Klasse „nobr“ – und die wird in jedem anderen <td> Element auch gesetzt, ist daher zur Filterung nutzlos. Schauen wir daher mal etwas über den Tellerrand, wie sieht es mit dem linken Tabellenfeld („Deutschland“) aus? Wesentlich besser, die Flagge des <span> Elements enthält eine Klasse flag-icon-de. Das Länderkürzel scheint eindeutig:
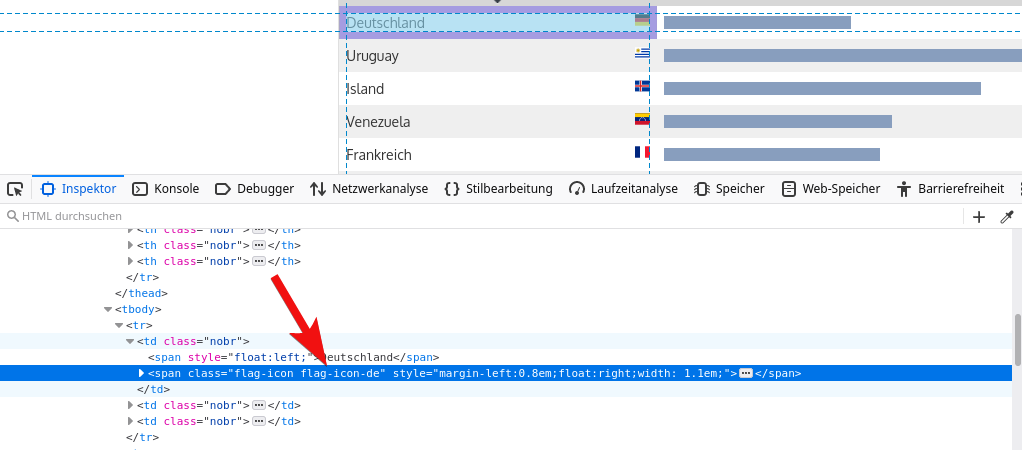
Allerdings zeigt eine Suche: Es wird an zwei anderen Stellen ebenfalls noch verwendet. Eine unsichtbare, gleich aufgebaute Tabelle und die Auswahlbox links unten, über die man die Sprache der gesamten Seite ändern kann.

Bei näherer Betrachtung der Struktur fällt auf, dass unsere Preistabelle aus der wir die Daten haben möchten, eine Id preisstaffelung besitzt:
<table class="grayedtable" id="preisstaffelung" style="width: 1095px;">
...
Damit können wir die zwei unerwünschten Elemente herausfiltern. Jedoch müssen wir nun noch einen zweiten Sprung machen, da wir ja nicht die Bezeichnung des Landes, sondern den BTP-Preis daneben haben möchten.
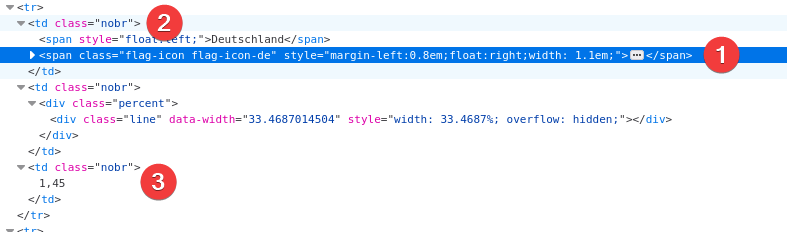
Bei (1) sind wir, dieses Element befindet sich in (2), wenn man eine Ebene höher geht. Es folgt ein zweites <td> Element, in dem sich der Balken für das Diagramm befindet. Schlussendlich bei (3) das letzte <td> Element, mit unserem gewünschten Wert. Unser Filter muss daher vom <span> Element mit der Klasse flag-icon-de ausgehend zwei Elemente zurück (Eltern-Elemente) und dann das dritte <td> Element auswählen.
price = driver.find_element(By.CSS_SELECTOR, "#preisstaffelung .flag-icon-de")
parentRow = price.find_element(By.XPATH, "../..")
priceElement = parentRow.find_element(By.CSS_SELECTOR, "td:nth-child(3)")
rawPrice = priceElement.get_attribute("innerHTML").strip()
print(rawPrice)
Hier nutzen wir den CSS-Selektor, um das Element mit der Flagge zu finden. Anschließend navigieren wir mit XPath zwei Elemente weiter nach oben in das <td> Element (2 auf dem obigen Screenshot). Wir könnten die Abfrage theoretisch auch komplett mit XPath umsetzen, das ist an der Stelle aber meiner Meinung nach als Einstieg zu komplex. Daher belassen wir es hier bei dem einfachen Selektor, der – ähnlich wie man es von Linux-Verzeichnissen her kennt, mit ../.. zwei Ebenen höher wechselt. Schlussendlich suchen wir das dritte <td> Element (3).
Die Ausgabe enthält jedoch Leerzeichen aus dem HTML, der strip() Aufruf entfernt vor- und nachgestellte Leerzeichen, sodass wir eine saubere Ausgabe erhalten:
$ python scrape.py
1,47
Weitere Hinweise und Tipps
Performance
Wie Anfangs erwähnt, wird im Hintergrund ein kompletter Chromium-Browser gestartet und ferngesteuert – bei jedem Aufruf des Skriptes. Dementsprechend beträgt die Ausführungszeit auf einem Raspberry Pi 4 mit 4GB RAM und dem Raspberry Pi OS 11 auf einer schnellen Micro-SD Karte ungefähr 13 Sekunden. Für finale Skripte, welche automatisch gestartet werden, ist das oft wenig relevant. Beim testen kann man ein Upgrade der Hardware versuchen, oder am besten gleich auf einer stärkeren Workstation entwickeln.
„Zombie“ Chromium-Prozesse durch Exceptions (Ausnahmen) beim Testen
Durch driver.quit() wird der Browser am Ende des Skriptes beendet. Falls beim Testen eine Exception auftritt, wird dieser Code aber nie erreicht – der Chromium-Prozess läuft dadurch weiter! Ohne grafische Oberfläche merkt man dies nicht sofort bzw. erst, wenn nach einigen Tests der Arbeitsspeicher voll läuft. Die Prozesse sollte man in diesem Falle von Hand beenden:
$ ps -ax | grep chromium | egrep -v "(<defunct>|grep)" | wc -l
7
$ pkill chromium
$ ps -ax | grep chromium | egrep -v "(<defunct>|grep)" | wc -l
0
Eine sinnvolle Alternative ist es, während der Tests den Code mit einem Try-Except-Block zu umschließen. Der „Finally“ Teil wird in jedem Falle ausgeführt, auch beim Auftreten einer Ausnahme. So kommt es im Fehlerfall zu keinen „Zombie Chromium-Prozessen“.
try:
driver.get('https://www.ebesucher.de/werbung/preise')
# ...
finally:
driver.quit()
Weitere Schritte und Fazit
In diesem Beispiel haben wir hauptsächlich mithilfe von CSS-Selektoren die Elemente gefiltert und erhalten mit jedem Aufruf des Skriptes den aktuellen Werbepreis für Deutschland. Als Nächstes sollten wir zumindest eine grundlegende Validierung einbauen, etwa ob die Elemente existieren und wir einen Zahlenwert erhalten.
Anschließend folgt das Abspeichern des Kurses zusammen mit dem Zeitstempel in einer Datenbank. Damit regelmäßig Daten erhoben werden, sollte das Skript in einem sinnvollen Intervall per Cron automatisch starten. Nach einiger Zeit kann man die Daten auswerten, visualisieren und daraus Schlüsse ziehen: Wie hat sich der Kurs entwickelt, wo gibt es Auffälligkeiten etc.