Wie viele Anfragen hält meine Webanwendung bzw. Webseite aus? Bleibt sie dabei stabil? Diese & weitere Fragen lassen sich durch künstlich erzeugte Last klären. In diesem Beitrag stelle ich das quelloffene Programm Oha vor: Es bietet eine Tui-Oberfläche und kann die Messwerte exportieren. Darüber hinaus gehe ich auf Aspekte ein, welche bei solchen Tests grundsätzlich beachtet werden sollten. Repräsentativ werden sie durch wiederholte Durchläufe, aus denen wir mit GNU/Linux Standardwerkzeugen den Durchschnitt berechnen.
Aufbau & Installation
Am einfachsten lässt sich Oha über die Binärdateien starten, welche in den GitHub-Releases veröffentlicht werden.1 Da eine ARM64-Edition existiert, kann man es ebenfalls auf dem Raspberry Pi sowie weiteren Einplatinencomputern nutzen. Zu beachten ist: Im Idealfall liegt der Webserver auf einer eigenen (Virtuellen) Maschine. Das macht den Test um so realistischer im Vergleich zu echten, organischen Besuchern.
Wie relevant das ist, hängt im wesentlichen davon ab, was man messen möchte. Geht es etwa um die Anzahl an Abfragen pro Sekunde, welche eine bestimmte Webanwendung verarbeiten kann, hat eine lokale Ausführung keine Nachteile. Allerdings sollte der Webserver möglichst identisch dimensioniert sein, wie das produktive System! Zumindest hinsichtlich des Arbeitsspeichers. Wer mit einem starken Desktop-Prozessor testet, wird bei CPU-Lastigen Anwendungen weitaus bessere Ergebnisse messen, als der ältere (und ggf. virtualisierte) Produktivserver.
Das ausführen gegenüber fremden Seiten ist zu unterlassen! Auch mit eigenen Servern in fremden Rechenzentren ist Vorsicht geboten: Der Test könnte als Angriff erkannt werden.
Der Unterschied zum Browser
Oha verhält sich nicht wie ein Webbrowser, der per HTTP-GET Anfrage die aufgerufene Adresse (zB / für das Wurzelverzeichnis) aufruft, das HTML parst & alle dort referenzierten Ressourcen (CSS, JS, Bilder usw) nachlädt. Sowie schlussendlich CSS & JS ausführt, womit ggf. weitere Anfragen folgen – etwa durch Ajax. Stattdessen wird beim Benchmark nur die initiale Anfrage auf die angegebene URL ausgeführt, ohne weitere Abhängigkeiten. Das ist kein grundsätzliches Problem. Man sollte sich dem jedoch bewusst sein. Die Last bei echten Abfragen kann höher sein, wenn z.B. per Ajax weitere dynamisch generierte Aufrufe folgen.
Theoretisch könnte man X Browser-Instanzen und Fernsteuern, ein bekanntes Framework dafür ist Selenium. Das macht jedoch wenig Sinn, weil es schnell an Grenzen stößt: Ein vollwertiger Browser verbraucht viele Ressourcen. Selbst auf leistungsstarker Hardware wird das Simulieren mit weniger als einer Hand voll Nutzern schnell scheitern. In aller Regel besteht dafür keine Notwendigkeit. Die initiale Anfrage belegt am meisten Ressourcen. Ausnahmen bilden Single-Page-Anwendungen, die eine statische HTML-Seite ausliefern. Per JS rufen sie APIs auf, welche dynamisch generiert mehr Leistung benötigen. Wer das einsetzt, hat sich eine Komplexität geschaffen, die sich bis zu den Tests durchzieht – einfache Werkzeuge wie Oha stoßen dabei an ihre Grenzen.
Wie viele parallele Prozesse?
Die Anzahl an gleichzeitigen Verbindungen sollte an die Konfiguration des Webservers angepasst werden: Anzahl der Arbeitsprozesse von Apache, PHP-FPM usw. Wie dies konkret aussieht, hängt vom eingesetzten Software-Stack ab. Wer beispielsweise PHP-FPM einsetzt, begrenzt die maximale Anzahl an Prozessen mit max_children:
pm.max_children = 50Erreichen mehr Anfragen den PHP-Server, muss dieser eine Warteschlange bilden. Folglich kommt es zu Verzögerungen.
Bei der Wahl für die Parameter -n (Gesamte Anzahl an Anfragen) und -c (Parallele Verbindungen) sollte die jeweilige Hardware berücksichtigt werden. Insbesondere die Gesamtanzahl an Anfragen darf nicht zu niedrig gewählt werden: Kurze Tests liefern weniger aussagekräftige Ergebnisse, weil einzelne Ausreißer viel stärker ins Gewicht fallen. Statt den gesamten Anfragen daher besser die parallelen Verbindungen reduzieren.
Durchführung der Messung
In diesem Szenario teste ich eine lokale Entwickler-Installation von U-News. Sie hat in ihrer docker-compose.yml sinnvolle Limits gesetzt bekommen, welche der produktiven Umgebung entsprechen. Da U-News bewusst sehr effizient entwickelt wurde, sind 100.000 Anfragen mit 100 parallelen Verbindungen sinnvoll. Der Test läuft unter diesen Bedingungen auf einem AMD Ryzen 9 3900X mit RAM-Begrenzung auf 512 MB für Webserver & PHP sowie 1 GB der Datenbank etwa 55 Sekunden lang.
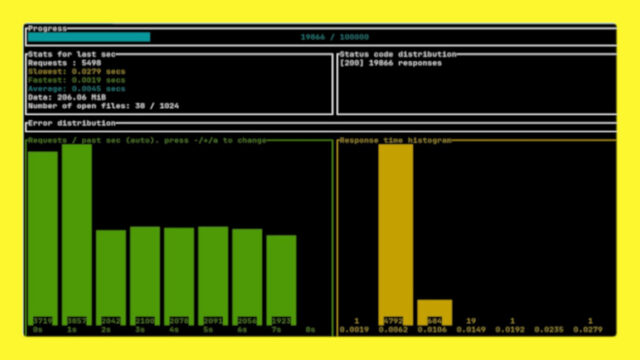
~/Downloads/oha-linux-amd64 --latency-correction --no-pre-lookup -n 100k -c 50 http://localhost/Damit erreiche ich in der Testumgebung einen Durchsatz von etwa 1.600 – 1.800 Anfragen pro Sekunde. Während die Messung läuft, zeigt das linke Diagramm an, wie viele Anfragen in der vergangenen Zeit ausgeführt werden konnten. Anfangs im Abstand von einer Sekunde, später erfolgt die Gruppierung in 10 Sekunden Blöcken. Rechts daneben die Dauer der Anfragen. Daraus lässt sich bereits ablesen, dass 100 Anfragen jeweils 4,5s gedauert haben – viel zu lang. Der Webserver ist also bereits überlastet und musste Anfragen einreihen. Allerdings konnten sie trotzdem abgearbeitet werden, es kam zu keinen Fehlern. Oben links sind weitere Statistiken sichtbar, sie beziehen sich nur auf die letzten 10 Sekunden. Am Fortschrittsbalken ganz oben ist zu erkennen, wie viele der insgesamt durchzuführenden Anfragen bereits abgearbeitet sind.
Nach Abschluss gibt Oha auf der Konsole einen Bericht aus: 100% Erfolgsrate bestätigt, dass keine Anfragen mit Fehlern abgebrochen worden sind. Interessant ist der Abstand zwischen schnellster & langsamster Anfrage sowie der Durchschnitt. Wie bereits während des Tests ersichtlich, benötigte ein Teil der Anfragen deutlich länger. In welchem Umfang, zeigen die unteren Bereiche besser: 99% sind in 0,0926s oder weniger bearbeitet worden. Die Anfragen pro Sekunde sind eine Metrik, mit denen sich unter identischen Bedingungen gut vergleichen lässt, ob etwas effizienter oder weniger effizient ist. Beispielsweise Caching aktivieren oder deaktivieren.
Repräsentative Ergebnisse mit mehr Messungen
Obwohl es sich um 100.000 Anfragen handelt, sollte man sich nicht auf lediglich einen einzelnen Durchlauf verlassen. Wer mehrere durchführt, wird Schwankungen feststellen. Keine all zu extremen, sie würden auf Probleme wie beispielsweise äußere Einflüsse hinweisen. Mein Test ergab eine Spannbreite von 1.600 Anfragen/s bis über 1.800 Anfragen pro Sekunde bei 10 Durchläufen, das ist normal und kann viele Ursachen haben. Ein klassisches Beispiel: Zwischenspeicher sind anfangs noch leer. Ich empfehle, den Durchschnitt aus fünf Messungen zu berechnen. Mindestens drei sollten es sein.
Requests/sec: 1634.1302
Requests/sec: 1785.7312
Requests/sec: 1829.8046
Requests/sec: 1795.9245
Requests/sec: 1778.8379
Requests/sec: 1606.8775
Requests/sec: 1827.2906
Requests/sec: 1853.2960
Requests/sec: 1856.0149
Requests/sec: 1804.9129Das muss nicht händisch gemacht werden, sondern lässt sich per Skript automatisch wiederholen:
for i in {1..5}; do
~/Downloads/oha-linux-amd64 --latency-correction --no-pre-lookup -n 100k -c 50 http://localhost/ | grep Requests
done
Requests/sec: 1836.0231
Requests/sec: 1484.0862
Requests/sec: 1557.1620
Requests/sec: 1494.4489
Requests/sec: 1513.5794Automatisches Schreiben & Auswerten der Ergebnisse
Praktisch hierfür ist die Ausgabe als JSON mittels --output-format json sowie optional das Schreiben aller Ergebnisse in eine Datei:
for i in {1..5}; do
~/Downloads/oha-linux-amd64 --latency-correction --no-pre-lookup -n 10k -c 50 --output-format json -o benchmark_$i.json http://localhost/
doneDas erzeugt die Dateien benchmark_1.json bis 5 im aktuellen Ordner. Mit Werkzeugen wie jq lassen sie sich parsen und gezielte Attribute abfragen, etwa die Anfragen pro Sekunde. Den Durchschnittswert rechnet uns awk aus:
jq -r '.summary.requestsPerSec' benchmark_*.json | awk '{sum+=$1; count++} END {print sum/count}'
2980.74Für jede Datei gibt jq dessen Wert an Abfragen pro Sekunde aus:
jq '.summary.requestsPerSec' benchmark_*.json
2968.0908715616397
3004.999176128391
5247.248777737877
2343.4296619530724
1339.9093700175113Er wird in awk zur Variable sum hinzurechnet. Parallel zählt count die Anzahl der Zeilen. Schlussendlich die aufsummierte Anzahl an Anfragen durch die Zahl an Zeilen (und damit Dateien der Messdurchläufe) teilen – in diesem Falle sind das durchschnittlich rund 2981 Anfragen/s.
Optimierungen/Konsequenzen
Hier handelt es sich bewusst um ein extremeres Beispiel, um die Grenzen auszutesten. Interessant ist, während des Tests die Auslastung des Servers zu beobachten: Der Flaschenhals ist mit einer Auslastung von bis zu 1.700% klar der Prozessor. Das liegt daran, weil hier aktuell noch ein simpler Apache2 mit mod_php (Prefork) eingesetzt wird. Er startet für jede Anfrage einen eigenen Prozess, der außerdem den PHP-Interpreter aufruft – das ist ineffizient. Mit PHP-FPM ließe sich zumindest auf Ebene von PHP die Last deutlich reduzieren. Der Einsatz eines auf Events basierten Webserver wie Nginx statt Apache würde zudem das ständige starten von vollwertigen Prozessen vermeiden.
In diesem Falle ist das bewusst in Kauf genommen. Die Seite verarbeitet zu Beginn weitaus weniger Anfragen. Außerdem wollte ich bewusst aufzeigen, wie weit man mit einem Standard-Apache + guten altem mod_php kommt: Damit lässt sich bereits einiges realisieren. Selbst auf einem relativ leistungsschwachen Raspberry Pi.
Je nach Ausgangslage & Ziel kann man nun entscheiden, ob die Werte zufriedenstellend sind. Oder optimiert werden müssen. Dabei geht es nicht zwingend um die Anzahl an Anfragen pro Sekunde, dies ist nur ein Beispiel. Dafür wären nun Optimierungen des Codes oder Caching geeignete Mittel. Anschließend erneut messen, um Veränderungen zu erfassen.
Wichtige Parameter für Oha
-n XXXXlegt fest, wie viele Anfragen insgesamt gesendet werden, bevor der Test abgeschlossen ist. Praktischerweise lassen sich Suffixe wie „k“ für tausend benutzen – 100k statt 100.000 anzugeben, ist kürzer und verbessert die Lesbarkeit.-c 100gibt die Anzahl an parallelen Verbindungen an und legt damit fest, wie schnell die Gesamtzahl abgearbeitet wird.--disable-keepalivemacht den Test realistischer, weil Keep-Alive Verbindungen wiederverwendet. Bei echten Besuchern funktioniert das natürlich nur begrenzt für nachgeladene Ressourcen, daher macht die Abschaltung Sinn. Allerdings kann man dadurch leicht an Limits stoßen, weil bei z.B. 100.000 Durchläufen eben 100.000 TCP-Verbindungen geöffnet werden.--no-pre-lookupverhindert, dass der übergebene DNS nur einmalig aufgelöst wird. Auch hier ein zweischneidiges Schwert: Realistischer ist die Auflösung vor jedem Lauf (also den Schalter setzen). Allerdings flutet man dadurch den DNS-Server mit zig tausend Anfragen. Das ist unproblematisch, wenn es sich um einen lokalen im eignen Netzwerk handelt (z.B. vom Router).--latency-correctionkorrigiert Latenz-Messfehler.--method POSTlegt eine andere HTTP-Methode fest, GET ist Standard. Damit kann man etwa testen, wie viele Übermittlungen eines Formulars parallel möglich sind. Dafür sind ebenfalls-d <body>oder-D <body-datei-pfad>notwendig: Ersteres übergibt den Body direkt, -D eine Datei, welche gesendet werden soll. Damit lässt sich etwa ein Dateiupload simulieren. Mit--form <werte>lassen sich HTML-Formulare übermitteln, im Format--form name=Peter.-a <basic-auth>authentifiziert die Anfrage per HTTP Basic Auth. Dies ist ein Base64 kodierter String im Format Benutzername:Passwort.- Wer mehrere URLs aufrufen möchte, kann sie in eine Datei schreiben und per
--urls-from-fileden Pfad übergeben. Dadurch ruft Oha alle Adressen auf. --insecureignoriert ungültige (z.B. selbst signierte) SSL-Zertifikate. Nützlich für lokale Testumgebungen.- Wie von Curl bekannt, erlaubt
-H <header>die Übergabe eigener HTTP-Header. Wird man eher selten brauchen, kann im Einzelfall jedoch wichtig sein – etwa bei Single-Page-Webanwendungen, welche ein JWT voraussetzen. - Statt die Ergebnisse auszugeben, lassen sie sich mit
--output-format json -o benchmark.jsonin eine JSON-Datei schreiben.
Alternativen
Oha ist ein Werkzeug mit grafischer Konsolen-Oberfläche (TUI), um Lasttests durchzuführen. Es existieren zahlreiche weitere, die im Kern das gleiche tun. Sie unterscheiden sich im Detail. Das älteste mir bekannte ist Apache Bench, kurz ab.2 Es wurde für Apache entwickelt, kann jedoch mit sämtlichen Webservern genutzt werden. Wie Oha sendet es Anfragen nach dem HTTP-Standard. Viele Funktionen sind vorhanden, teils mit anderen Formaten. So kann Apache Bench zwar die Messergebnisse ebenfalls in eine Datei schreiben. Statt JSON werden CSV und Gnuplot unterstützt.
Wer eine grafische Desktop-Oberfläche bevorzugt, ist JMeter.3 Es stammt ebenfalls von der Apache Software-Organisation und grenzt sich nicht nur optisch ab: Die Java-Anwendung ist für allgemeine Lasttests entwickelt worden. Neben HTTP funktioniert es für zahlreiche weitere Protokolle wie FTP, JDBC, LDAP, Mail und weiteren. Generell ist JMeter mächtiger, beispielsweise beim ausführlicheren aufbereiten der Messwerte.4