
Ansible ist ein beliebtes quelloffenes Automatisierungswerkzeug. Es kann Zeit sparen, die Qualität eurer Systeme verbessern und nebenbei auch dokumentieren. Dieser Beitrag bietet einen ersten Einstieg in die Automatisierung mit Ansible für Anfänger. Dabei spielt es keine Rolle, ob du einen physischen/virtuellen Server, Raspberry Pi oder Server in der Cloud automatisieren möchtest.
Wie kann ich mir Ansible vorstellen?
Man beschreibt in einem sogenannten Playbook den gewünschten Zielzustand in einzelnen Aufgaben (Tasks). Eine davon könnte etwa ein Paket installieren, eine bestimmte Zeile soll in einer Konfigurationsdatei stehen, eine Datei an einen bestimmten Ort herunterladen usw. Die Aufgaben erledigen das gleiche wie bei einer händischen Installation: Etwa Apache mit PHP installieren, das PHP-Modul aktivieren und eine Test-PHP Seite platzieren.
In Konsequenz heißt das aber auch, dass man die manuelle Installation beherrschen muss, um sie in Ansible umsetzen zu können. Oder anders gesagt: Wer die gewünschte Umgebung nicht ohne Ansible installieren kann, dem nützt Ansible nicht viel. Es ist vielmehr ein Hilfsmittel wie eine Kreissäge gegenüber der Handsäge mit dem Schreiner. Wer das Handwerk nicht beherrscht, der wird durch die Kreissäge aber nicht zum Schreiner.
Zur Beschreibung des gewünschten Zustandes wird Yaml verwendet. Die Auszeichnungssprache kennen einige sicher bereits von Docker-Compose oder Kubernetes. Sie ist leicht erlernbar und abstrahiert teils Unterschiede von verschiedenen Distributionen. Falls notwendig, kann man solche auch selbst behandeln und etwa bestimmte Schritte nur für einzelne Distributionen/Betriebssystemfamilien durchführen.
Gegenüber der händischen Installation bietet Ansible mehrere Vorteile:
Zustandsorientiert
Viele Ansible-Module sind idempotent – sie prüfen also erst den aktuellen Zustand und nehmen Änderungen nur bei Bedarf vor. Auch bei mehrfacher Ausführung kommt es dabei zu keinen unerwünschten Nebeneffekten.
Ein einfaches Beispiel:
echo "Test 123" >> /etc/httpd/httpd.confFührt man dies mehrfach aus, würde die Anweisung auch mehrfach in der Konfigurationsdatei stehen – je nach Anwendung verursacht dies Probleme.
Mit einem Shell-Skript könnte man zwar ein ähnliches Ergebnis wie mit Ansible erreichen, in dem entsprechende Prüfungen durchgeführt werden, falls notwendig. Das erhöht allerdings die Komplexität und schafft schnell Redundanzen, wenn unterschiedliche Prüfungen in verschiedenen Skripten immer wieder benötigt werden. Außerdem gibt es bei Shell-Skripten einige Fallstricke. Sie werden mit steigendem Umfang zunehmend fehleranfällig.
Dokumentiert
Konsequent eingesetzt, ist die gesamte Installation und Einrichtung der Software in Yaml-Playbooks beschrieben. Im besten Falle versioniert man diese mit Git. Damit haben wir eine gewisse Dokumentation und können über den Verlauf im Git-Repository sogar nachvollziehen, wann etwas geändert wurde.
Natürlich könnte man auch hier eine händische Dokumentation schlichtweg manuell dokumentieren. In der Praxis wird das aber oft vernachlässigt. Dies führt zu Systemen, die man nur schwer warten oder gar neu installieren kann, weil niemand mehr genau weiß was alles darauf läuft und wie es eingerichtet wurde.
Effizient, v.a. mit mehreren Systemen
Einer der wohl größten Vorteile liegt in der Effizient, wenn man mehrere Systeme verwaltet: Einmal geschrieben und getestet, kann ein Playbook auf 2, 10 oder 100 Systeme angewendet werden. Das spart Zeit und reduziert die Anfälligkeit von händischen Fehlern.
Sogar Parallel. Im Inventory gibt man die Server an. Darin lassen sich beliebige Server in Gruppen einteilen. So lässt sich festlegen, dass etwa auf alle Server in der Gruppe „Webserver“ ein Apache2 installiert und eingerichtet wird. In der Gruppe „Datenbankserver“ dagegen eine MySQL-Instanz. Auch andere Szenarien sind denkbar, etwa alle Aktualisierungen auf sämtlichen Testsystemen einzuspielen.
Konsistenz
Ein weiterer Vorteil: Man erhält exakt die gleiche Umgebung. Auch das ist händisch oft nicht gegeben, weil man z.B. auf einem System mal etwas ausprobiert hat oder sich nicht mehr an die genaue Installation erinnert.
In der Praxis ist das etwa hilfreich, um Testsysteme und Produktivumgebungen identisch zu installieren. Hier möchte man keine (ungewollten) händischen Abweichungen, da so Probleme möglicherweise nicht vorab erkannt werden, sondern erst produktiv auftreten. Oder wenn man einen Cluster aufsetzt. Auch hier benötigt man mehrere Server, die alle gleich oder zumindest ähnlich aufgebaut werden sollen.
Leichtgewichtig und einfach
Auch andere Werkzeuge wie beispielsweise Puppet ermöglichen Automatisierung. Allerdings wird hier oft ein Agent auf jedem System installiert. Das hat seine Vor- und Nachteile. In großen Umgebungen ist eine zentrale Client-Server Verwaltung sicher hilfreich. Allerdings erhöht es die Komplexität und der Agent verursacht etwas Last auf dem System.
Ansible dagegen benötigt neben SSH-Zugriff und Python keine weiteren Abhängigkeiten.
Warum sollte man automatisieren? Lohnt sich das?
Einige der Vorteile machen je mehr Sinn, um so größer/wichtiger die Umgebung ist. Hier bietet Automatisierung die unbestreitbaren Vorteile von einer höheren Effizienz und Konsistenz. In kleineren Umgebungen kann man das – zu Recht – hinterfragen. Hier kommt es auf den Einzelfall an, da man auch mit weniger Systemen von manchen Vorteilen profitieren kann. Möglicherweise ist der händische Weg hier sinnvoll, wenn man nur sehr wenige Systeme hat und keine getrennten Testumgebungen. Auch für erste Gehversuche würde Ansible mehr Komplexität schaffen.
Wer in der IT arbeitet oder arbeiten möchte, für den kann sich die Einarbeitung in Ansible aber auch aus anderen Gründen lohnen: Man hat Erfahrung gesammelt und belegt damit indirekt, dass man sich selbst in neue Themen einarbeiten kann. Das kann ein Pluspunkt im Lebenslauf sein. Vor allem bei jenen Unternehmen, welche die Fähigkeiten des Bewerbers statt seiner formalen Abschlüsse in den Mittelpunkt stellen.
Ansible in der Praxis
Im Folgenden schauen wir uns ein sehr einfaches Playbook an. Es installiert Apache2 auf einem Debian/Raspberry Pi OS und ersetzt die Standard index.html Seite mit einer eigenen.
- name: Apache auf dem Raspberry Pi installieren
hosts: all
tasks:
- name: Apache2 installieren
become: true
apt:
name: apache2
# Aktualisiert zuvor die Paketquellen (entspricht apt update)
update_cache: yes
- name: Eigene Index-Seite anlegen
become: true
copy:
dest: /var/www/html/index.html
content: "<b>Demo</b>: Apache-Installation per Ansible"
Im Attribut hosts könnten wir spezielle Gruppen angeben, auf denen das Playbook ausgeführt werden soll. Zur Vereinfachung habe ich das hier nicht weiter eingeschränkt. Interessanter sind die Aufgaben: Der Bereich tasks enthält eine Liste von Aufgaben. Die erste Aufgabe installiert das APT-Paket apache2 mit Sudo (become), d.H. im Grunde sudo apt install apache2. Mit update_cache stellen wir sicher, dass die Paketquellen aktuell sind. Dies entspricht einem Aufruf von apt update vor der Installation. Der Name ist jeweils frei wählbar und dient der Zuordnung (siehe unten).
Aufgabe 2 schreibt eine Zeile in die Standard-Indexdatei unter /var/www/html/index.html. Dies geschieht ebenfalls mit Root-Rechten. Sauberer wäre es, zuvor unseren Nutzer entsprechend zu berechtigen – auch das habe ich hier zur Vereinfachung weggelassen. Normal würde man in einem Inventory die IPs oder Hostnamen der Zielsysteme angeben und ggf. Gruppen definieren. Für einen einfachen Test mit einem System reicht der händische Aufruf (das Komma nach dem Hostname muss gesetzt sein). Wichtig: Zuvor die Authentifizierung per SSH-Schlüssel (ssh-copy-id) einrichten.
ansible-playbook -i pi, --user pi playbooks/apache_demo.yml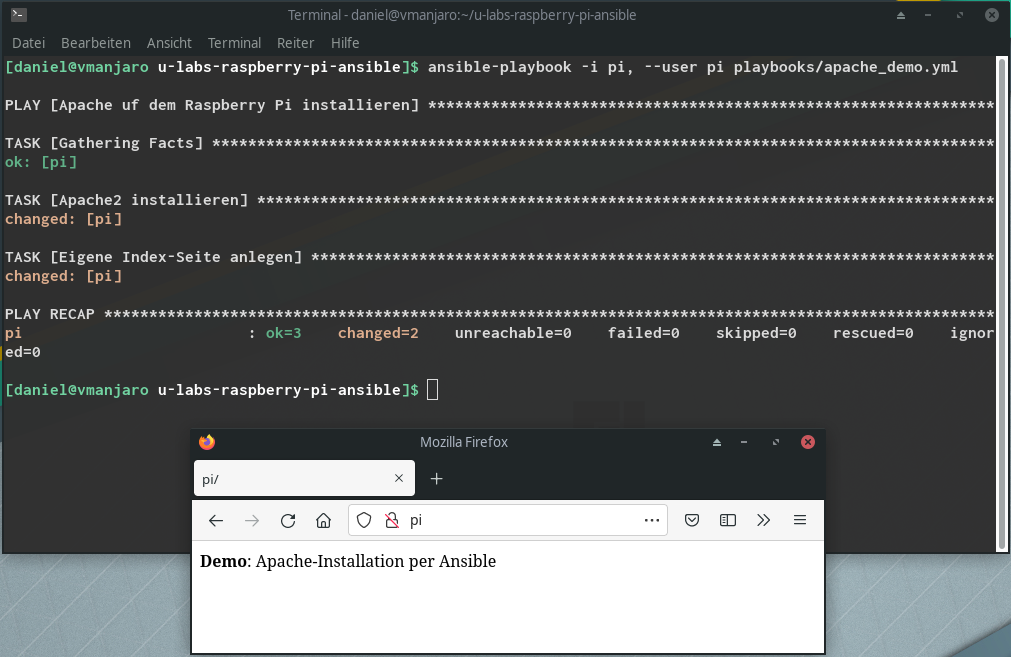
Damit haben wir ein erstes, einfaches Playbook entwickelt. In der Praxis würde man nun natürlich noch detailliertere Aufgaben einbauen, um alles was man benötigt entsprechend zu installieren und einzurichten. Dass Ansible wie zuvor erwähnt zustandsorientiert ist, können wir an dieser Stelle testen, in dem man das Playbook erneut startet:
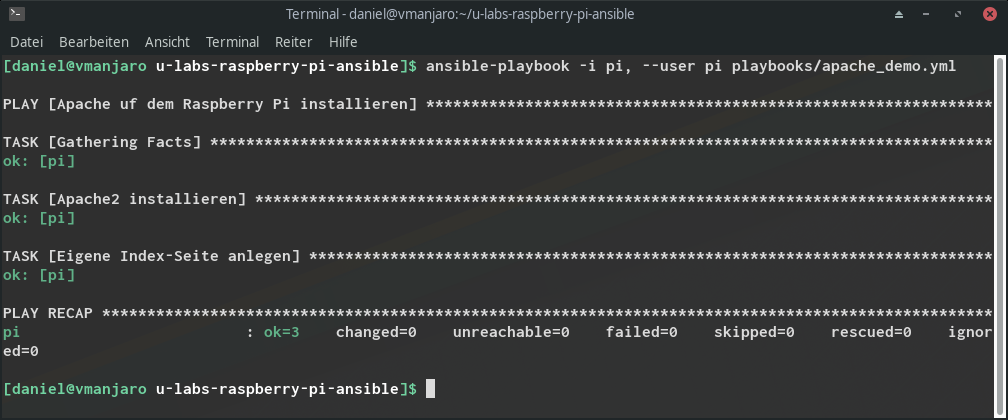
Dieses Mal ist alles grün, das heißt: Ansible hat erkannt, der gewünschte Zustand (z.B. Apache installieren) ist bereits erreicht – daher muss nichts unternommen werden. Zuvor waren unsere beiden Aufgaben gelb, da sowohl das Apache-Paket als auch unsere eigene Indexseite noch fehlten.
Weitere Schritte
Diese erste Einführung soll nur einen Überblick bieten und ist nicht auf alle Details von Ansible eingegangen. Beispielsweise Module, Variablen, Templates, Kontrollstrukturen wie Schleifen, Rollen, usw. Komplexere Playbooks strukturiert man zur besseren Übersichtlichkeit in einer Rolle. Diese kann wiederum in einem Playbook importiert werden. Anpassungen sind mit Variablen möglich. Wer komplexere Konfigurationsdateien erstellen möchte, greift auf Templates zurück. Auch dort gibt es Variablen, Schleifen und weitere Hilfsmittel.