
Diesmal trifft es mit abload.de und filehostr.de vom gleichen Betreiber ein Urgestein. Über 94.000.000 Bilder wurden auf Abload in den fast 18 Jahren des Bestehens gespeichert. Auch auf U-Labs war dieser Hoster beliebt: Mehr als 2.200 Bilder drohen, für immer Verloren zu gehen. Es wird daher Zeit für eine Rettungsaktion.
Was ist Abload.de?

Der 2006 gestartete Dienst des damals 17-Jährigen Gründers war mit dem Ziel angetreten, kostenlosen Bildspeicher für jeden bereitzustellen. Seit 2007 kann man die Änderungen im hauseigenen Blog nachverfolgen.1 Dort berichtet der Gründer bereits 2021 von fast 90 Millionen hochgeladenen Dateien in 15 Jahren. Auch das erste Testbild von damals sei noch online. 2 Und das kaufe ich ihm sofort ab: Über Jahre hinweg hat sich Abload in meiner Erfahrung als sehr zuverlässig erwiesen. Das älteste von mir persönlich im Konto hochgeladene Bild stammt von 2013, es ist auch 2024 abrufbar.
Aus heutiger Sicht mag es erklärungsbedürftig sein, warum man solch einen Bildhoster benötigt(e): Vor einigen Jahren war Speicher teuer und auch der Datenverkehr (Abruf von z.B. auf Servern gespeicherter Bilder) begrenzt. Sie wurden daher häufig für Blogs, Foren, Verkaufsplattformen wie eBay sowie andere Webseiten verwendet. Besonders praktisch ist das, wenn ein Bild an mehreren Stellen benötigt wird. Etwa für Bildschirmfotos: Verbreitete Programme wie ShareX bieten das automatische Hochladen an. Der Link lässt sich per Messengern verschicken, eben so in Foren oder auf dem Blog einbinden. Ob und wo das passiert, entscheidet der Nutzer selbst. Es gibt keine öffentliche Liste aller Bilder, wie auf Instagram & co.
Über die letzten Jahre hat das sicher abgenommen, weil sich ein erheblicher Teil der Aktivität auf (kommerzielle) soziale Netzwerke verlagerte. Sie laden alle Inhalte auf eigene Server. Die Kosten dafür sind vernachlässigbar: Schließlich lässt sich durch das massenhafte Sammeln und Verkaufen von Nutzerdaten extrem viel Geld verdienen. Neben den allgemein gesunkenen Speicherpreisen haben sich zudem ein paar weitere Rahmenbedingungen verändert. Beispielsweise verlangte eBay früher einen Aufpreis für weitere Bilder. Da in der Beschreibung HTML und sogar JavaSkript erlaubt waren, betteten einige die Bilder per HTML <img> Element in die Beschreibung ein. Selbst kostenpflichtiger Speicher hätte sich dafür schnell gerechnet. Dank zuverlässiger Diensten wie Abload war das gar nicht zwingend nötig.3Über die letzten Jahre hat das sicher abgenommen, weil sich ein erheblicher Teil der Aktivität auf (kommerzielle) soziale Netzwerke verlagerte. Sie laden alle Inhalte auf eigene Server. Die Kosten dafür sind vernachlässigbar: Schließlich lässt sich durch das massenhafte Sammeln und Verkaufen von Nutzerdaten extrem viel Geld verdienen. Neben den allgemein gesunkenen Speicherpreisen haben sich zudem ein paar weitere Rahmenbedingungen verändert. Beispielsweise verlangte eBay früher einen Aufpreis für weitere Bilder. Da in der Beschreibung HTML und sogar JavaSkript erlaubt waren, betteten einige die Bilder per HTML <img> Element in die Beschreibung ein. Selbst kostenpflichtiger Speicher hätte sich dafür schnell gerechnet. Dank zuverlässiger Diensten wie Abload war das gar nicht zwingend nötig.
Warum Abload sein 20-Jähriges Jubiläum nicht mehr erreicht
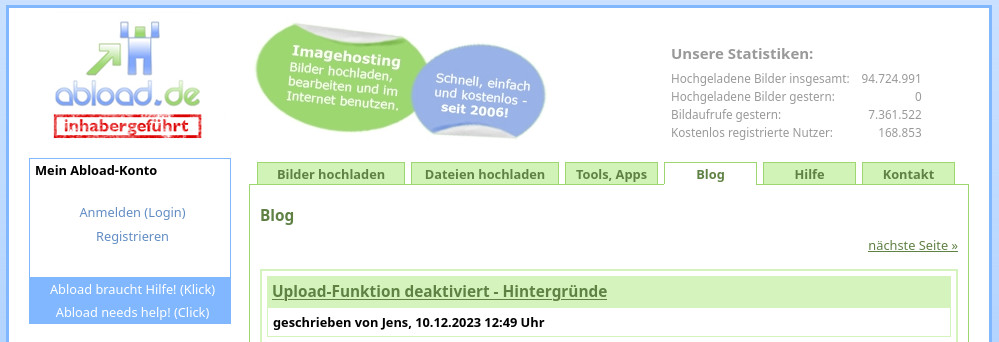
Wenn man nicht selbst für einen Dienst bezahlt, gibt es meist nur zwei Möglichkeiten: Entweder ist man selbst das Produkt, wie bei den kommerziellen Sozialen Netzwerken. Oder jemand anders bezahlt. Das ist bei Abload der Fall, sie leben von Werbung und Spenden. Laut Betreibern decken sie damit die Kosten für die Infrastruktur. Die Pflege des Dienstes selbst erfolgt in ihrer Freizeit, ist also nicht auf kommerzielle Gewinne aus. Bereits im Dezember 2023 musste das Hochladen neuer Bilder eingestellt werden. Anlass war eine Speichererweiterung für die stetig wachsende Menge an Daten.4 Denn auch wenn Abload nicht mehr so stark frequentiert sein mag, wie noch vor einigen Jahren – es mussten immer noch täglich tausende neue Bilder gespeichert werden.
Konkret nennt der Gründer folgende Ursachen, weswegen Abload zum 30.06.2024 eingestellt wird:5
- Die Betriebskosten steigen
- Sinkende Einnahmen
- Höhere Verpflichtungen durch gesetzliche Anforderungen/Anwaltliche Beratung
- Geänderte Lebensumstände der Betreiber
Es ist klar, dass trotz langfristig gesunkener Speicherpreise die Betriebskosten bei täglich wachsender Datenmenge steigen. Punkt #2 ist ebenfalls nachvollziehbar – insbesondere, wenn die Einnahmen parallel sinken. Werbeblocker verbreiten sich seit Jahren zunehmend und die Spendenbereitschaft sinkt auch durch andere Entwicklungen. Wer beispielsweise eine (Next-) Cloud verwendet, kann Bilder sowie weitere Daten im kleineren Personenkreis direkt dort teilen. In vielen Sozialen Netzwerken sind ohnehin keine externen Hoster mehr nötig. Betreiber von Blogs oder Foren nutzen lokale Möglichkeiten, sofern sie ihren Betrieb nicht ebenfalls bereits eingestellt haben.
Das Sterben der Bildhoster
Dabei handelt es sich nämlich um keinen Einzelfall. Im Jahresrückblick 2023 hatte ich neben dem Lesemodus von Abload noch vier weitere Beispiele von Bildhostern erwähnt, die in den Jahren zuvor ihre Dienste eingestellt haben. Ein weiteres Beispiel ist folgender Ordner aus meinen alten Lesezeichen, in denen ich 2014 insgesamt 9 Bildhoster abgelegt hatte:

Lediglich drei davon sind zehn Jahre später noch online:
- img5.cc
- pic-upload.de
- xup.in
Eingestellt:
- picload.org – leitet auf abload.de weiter. Laut einer Info-Seite wurde picload 2019 eingestellt und die Abload-Betreiber haben angeboten, dessen Bilder zu übernehmen. Die jeweiligen Nutzer mussten dafür ihr Einverständnis geben.6
- picspeicher.de
- imgimg.de – zeigt seit geraumer Zeit nur 403 Forbidden. Sowohl auf der Startseite, als auch auf Links zu Bildern.
- jaypac.de
- image-load.net – Auf Startseite und Links zu Bildern wird ein HTTP Basic Authentifizierungsdialog angezeigt
- bild5.de – Ebenfalls 403 Forbidden
Und das ist nur ein Auszug. Diese Liste könnte man noch weiter führen, ein paar Beispiele die 2014 noch online waren:
- imgbox.de ist viele Jahre online gewesen. Seit längerem liefern sie ein ungültiges TLS-Zertifikat aus und auch wer das ignoriert, sieht lediglich eine 503 Service Temporarily Unavailable Fehlerseite.
- img4web.com lädt gar nicht mehr
- yourupload.de leitet auf eine Verkauffseite für die Domain
Selbst Archivseiten helfen kaum: „Eco“ möchte Abload nicht archivieren
Sind Webseiten nicht mehr verfügbar, kann man mit verschiedenen Archivdiensten möglicherweise die Inhalte noch abrufen. Das ist zwar bei weitem keine Garantie: Selbst die größten Archive haben nur einen kleinen Bruchteil des Internets archiviert. Möglicherweise zu einem Zeitpunkt, an dem die gewünschten Inhalte noch nicht oder nicht mehr auf der Seite vorhanden waren. Dazu kann es zu Problemen kommen, vor allem bei Multimedia-Inhalten wie Bildern oder Videos. Diese benötigen deutlich mehr Speicher als Text und sind daher ein Kostenfaktor.
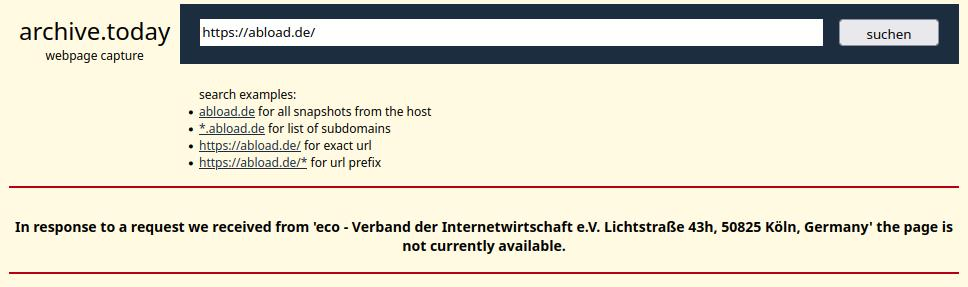
Wer beispielsweise auf archive.li nach abload.de sucht,7 wird noch ein Problem feststellen: Der „eco – Verband der Internetwirtschaft e.V.“ hat etwas dagegen und anscheinend sämtliche Treffer zu Abload entfernen lassen. Selbst mit https://abload.de/* werden keine Ergebnisse angezeigt. Damit entfällt selbst dieser letzte Strohhalm, um ggf. nach dem 30.06.2024 bis dahin ungesicherte Bilder retten zu können.
Die Probleme: Verschwundene Bildhoster machen das Internet kaputt
Bei manchen handelt es sich um kleinere Dienste, die nur ein paar tausend oder zehntausend Bilder enthielten. Aber auch diese sind weg, falls der Betrieb eingestellt wird. Möglicherweise ohne Vorwarnung – nicht jeder gewährt den Nutzern zumindest einige Wochen Zeit, um ihre Bilder umzuziehen. Insbesondere bei großen Anbietern sind die Verluste gewaltig. Tinypic beispielsweise war 15 Jahre lang online und zur Blütezeit sehr beliebt.8 Alleine Abload stellte Ende 2023 über 94,7 Millionen Bilder zur Verfügung, die etwa 7,361 Millionen mal am Tag aufgerufen werden.
Diese Bilder sind überall im Web verstreut. Selbst mit Vorlaufzeit müssten Betroffene über das baldige Ende von Abload informiert sein und rechtzeitig alle Bilder umziehen. In größeren Blogs oder Foren beispielsweise keine leichte Aufgabe.
Die Lösung: So retten wir über 2.200 Bilder
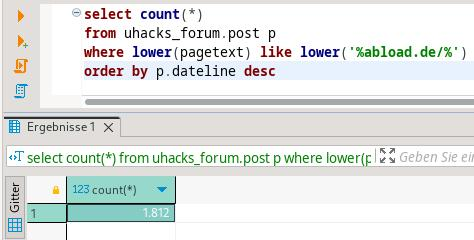
Alleine auf U-Labs zeigt eine schnelle Volltextsuche nach abload.de/ über 1.800 betroffene Beiträge. Insgesamt sind darin mehr als 2.200 Bilder zu Abload verlinkt. Die Zahlen weichen voneinander ab, da manch ein Beitrag mehrere Bilder enthält.
Das Problem wurde auf U-Labs bereits 2012 erkannt: Im selben Jahr startete unser eigener Bildhoster U-IMG. Externe Dienste haben eine Reihe an Nachteilen. Wir wurden sogar einmal in Chrome blockiert, weil wir ein Bild von einer angeblich verseuchten Seite eingebunden haben. Um den Wildwuchs einzudämmen und die Nutzer zur Verwendung von U-IMG zu animieren, gibt es zur direkten Einbettung seit dem gleichen Jahr eine Liste erlaubter Anbieter. Dort befinden sich 11 externe Dienste, darunter unter anderem Abload. An dieser Stelle rächt sich, dass diese Liste danach nicht Schrittweise eingeschränkt wurde. Zumindest für neue Beiträge wäre das sinnvoll gewesen. Dennoch liefert U-IMG tausende Bilder aus und hat sicherlich dazu beigetragen, diese nachhaltig, performant sowie datensparsam für die Nutzer bereitzustellen. Die grundsätzliche Entscheidung für U-IMG sehe ich an dieser Stelle bestätigt.
Als Betreiber von U-Labs kann ich zumindest hier etwas tun: Die Links auf Abload aus allen Beiträgen extrahieren, das jeweilige Bild herunterladen und auf meinem eigenen Bildhoster U-IMG hochladen. Bei über 1.800 Beiträgen muss dies automatisiert erfolgen: Manuell wäre dies zu zeitaufwändig. Außerdem ist es eine monotone Tätigkeit, die schnell nervt. Darüber hinaus gibt es eingebettete Bilder auf anderen Diensten. Es wird höchste Zeit, im nächsten Schritt auch diese umzuziehen – bevor in ein paar Monaten oder Jahren der nächste Anbieter den Stecker zieht oder ziehen muss.
Wie zieht man so viele Bilder um?
In diesem Abschnitt beschreibe ich meine Vorgehensweise beim Umzug. Nicht bis ins letzte Detail und jeder einzelnen Zeile Code. Sondern als Zusammenfassung der wichtigsten Punkte.
Wonach suchen wir genau?
Für das ermitteln der betroffenen Beiträge habe ich mit where lower(pagetext) like '%abload.de%' bewusst sehr breit gesucht: Zwar ist mir das Format eines Direktlinks mit https://abload.de/img/{Dateiname}.{Endung} bekannt. Allerdings existiert das U-Labs Forum seit Ende 2011. Erfahrungsgemäß kann sich in fast 13 Jahren einiges verändern. Bilder, die ich jetzt nicht finde, fallen unter derzeit über 327.000 Beiträgen bestenfalls auf, wenn Abload längst vom Netz ist. Für einen groben Überblick habe ich mir daher bewusst jene Beiträge anzeigen lassen, die abload.de enthalten und nicht auf das obige Muster passen. Hier fiel wie erwartet auf: Manche ältere Direktlinks erhalten www als Subdomain. Andere allerdings auch andere, zudem in verschiedenen Formaten.
http://h-4.abload.de/img/dbqtyn.png<br>http://h10.abload.de/img/asd37qcf.jpg
Wahrscheinlich hat Abload anfangs die Bilder auf einzelne Server verteilt und leitete über die Subdomains direkt darauf. Später lief alles zentral über einen Loadbalancer auf abload.de, bis man zwischendrin noch das Format (Bindestrich) geändert hat. Damit war klar: Ich musste Subdomains ebenfalls berücksichtigen. Am besten universell, da weitere Formate existieren können, die mir in der Masse bisher nicht aufgefallen sind.
Wie suchen wir?
Mein erster Ansatz war, nach [IMG] BBCodes zu suchen, die abload.de enthalten. Der Gedanke dahinter war: Bilder werden in der Regel eingebettet, [IMG] ist mit einem HTML <img> Element vergleichbar. Dabei wurde mir etwas deutlich, was ich bisher gar nicht auf dem Schirm hatte: Vorschaubilder (Thumbnails). Statt die Bilder direkt in voller Größe einzubetten, wird ein verkleinertes Bild in einem [URL] Element geschachtelt. Das verbraucht weniger Platz und hält den Beitrag übersichtlich, insbesondere bei größeren/mehreren Bildern. Der Imagehoster freut sich über Werbeeinblendungen, falls jemand auf das Bild klickt und es auf der Seite des Anbieters in größerer Version betrachtet.
[url=https://abload.de/image.php?img=2021-11-17_09-41-163uk0d.png][img]https://abload.de/thumb/2021-11-17_09-41-163uk0d.png[/img][/url]
Hier wäre es natürlich unsinnig, lediglich das kleine Vorschaubild zu ersetzen. Vor allem wenn lediglich das kleine Bild hochgeladen werden würde. Darüber hinaus hat nicht jeder Nutzer von der Einbettung Gebrauch gemacht – manche fügen lediglich den Link ein. Der von Abload bevorzugte Anzeigelink (welcher im Gegensatz zum Direktlink Werbung einbettet), führt zu image.php?img= gefolgt vom Dateiname. In den Tests sind noch weitere Dinge aufgefallen. So schreibt Abload im Pfad „/thumb/“ die Abmessungen und Dateigröße unten auf das Bild, bei „/thumb2/“ nicht.
Was ist, wenn ein Link möglicherweise nicht klickbar in z.B. einem Element verschachtelt ist? Oder jemand hat nur die Vorschau ohne Verlinkung eingebettet? So was kann unter tausenden Beiträgen passieren, insbesondere von technisch weniger erfahrenen Nutzern. Es schien mir daher nicht sinnvoll, strikt die BBCodes zu parsen.
Ich habe stattdessen einen regulären Ausdruck entwickelt, der alle Formate abdeckt:
#http(?:s)?://(?:[a-z0-9\-]+\.)?abload.de/(?:img/|thumb(?:2)?/|image\.php\?img=)[0-9a-z_\-\.]+\.[a-z]{3,4}#
Welches Format ich davon bekomme, ist mir am Ende egal - mir geht es an dieser Stelle um den Dateiname. Alles andere ist daher als non-capturing group aus den extrahierten Daten ausgeschlossen und dient nur zur Mustererkennung. Nachdem mir dies nicht vollständig von Anfang an klar war, habe ich zunächst sogar nur das gesamte Match (also die vollständige URL) genommen und anhand bestimmter Merkmale vereinheitlicht. Als Ziel sollte danach immer der direkte Link heraus kommen, um die originale Datei herunterzuladen.
// Vorschaubilder zum einbetten ([img] in [url] geschachtelt)
if(strpos($imgDirectUrl, 'abload.de/thumb') !== false) {
$imgDirectUrl = str_replace('abload.de/thumb/', 'abload.de/img/', $imgDirectUrl);
}
// HTML Seite mit eingebettetem Bild - Umwandlung zum Direktlink für Download
if(strpos($imgDirectUrl, 'image.php') !== false) {
//$imgName = explode('img=', $imgDirectUrl)[1];
$imgDirectUrl = str_replace('image.php?img=', 'img/', $imgDirectUrl);
}Herunterladen der Bilder
Hierfür nutze ich ein lokales temporäres Verzeichnis und generiere einen SHA256 Hash des originalen Dateinamens. Nur um sicher zu gehen, kein Potenzial für Injections im Dateipfad zu haben. Zwar erwarte ich das bei Abload nicht. Aber Vorsicht ist besser als Nachsicht. Insbesondere, nachdem viele Anwendungen für derart triviale Angriffe verwundbar sind und ich das ganze hier vorstelle. Im Zweifel bedenkt man das beim nächsten Projekt sonst ebenfalls nicht, wo sich derartiges über einen einfachen HTTP POST Parameter oder vergleichbar ausnutzen lässt.
Für das Herunterladen selbst kommt die cURL Bibliothek in PHP zum Einsatz.9 Sie ist etwas sperrig, zumal die meisten Aufrufe auch 2024 immer noch rein prozedural erfolgen. PHP selbst bietet seit längerem OOP mindestens als Alternative an. Allerdings ist sie stabil und nimmt einem etwas Arbeit ab, die man ansonsten durch komplett eigene Implementierung des HTTP-Protokolls hätte. Beispielsweise kann die Antwort (= das Bild als binäre Datei) vergleichsweise einfach in eine Datei geschrieben werden.
$hashedName = hash('sha256', $name);
$tmpPath = "/abload_tmp/$tmpName";
$tmpFile = fopen($tmpPath , 'w');
$ch = curl_init();
curl_setopt($ch, CURLOPT_FILE , $tmpFile);
curl_setopt($ch, CURLOPT_URL, $abloadUrl);
// ...Und wieder hochladen
Hier kommt ebenfalls wieder curl zum Einsatz. Theoretisch sollte das der einfachste Teil sein, weil ich als Betreiber von U-IMG alles beliebig anpassen kann. In der Praxis brauchte es doch etwas Zeit an anderer Stelle: In der PHP-Implementierung war es lange Zeit üblich, den Pfad als Formularfeld im HTTP POST Body zu übergeben. Ein vorangestelltes '@' sorgt dafür, dass die Datei im Hintergrund geöffnet und ihr Inhalt eingefügt wird, statt den Pfad als Zeichenkette zu versenden:
$body = array(
'file' => "@" . $localFile
);
curl_setopt($ch, CURLOPT_POSTFIELDS, $body);Seit PHP 5.5 wird dieses Verhalten über die Variable CURLOPT_SAFE_UPLOAD gesteuert: Nur wenn sie auf False steht, funktioniert dieser Weg. In PHP 5.6 wurde sie auf True geändert, um sie später komplett zu entfernen.
NOTICE: PHP message: PHP Fatal error: Uncaught ValueError: curl_setopt(): Disabling safe uploads is no longer supportedTatsächlich gibt es mit CURLFile sogar eine Klasse dafür. Die ist nicht nur deutlich sauberer, sondern unterstützt auch weitere Meta-Informationen wie Mime-Typ oder zu sendender Dateiname. In einer Stackoverflow-Frage zu diesem Thema mit 30.000 Aufrufen war das bisher noch nicht derart klar dokumentiert, habe ich dort eine Antwort geschrieben.10
$file = new CURLFile($path, 'image/' . $type, $name);
$body = array('file' => $file);
curl_setopt($ch, CURLOPT_POSTFIELDS, $body);Aktualisieren des Beitragstextes
2/3 Schritte sind damit abgeschlossen. Abschließend müssen die alten Abload-Links noch im Beitrag ersetzt werden. Da es auch hier mehrere Varianten gibt, beginne ich mit dem typischsten: Eingebettet als verlinktes Vorschaubild. Hier soll das Vorschaubild durch das von U-IMG ersetzt werden. Aber auch der Link auf das volle Bild - sonst läuft dieser nach dem Abschalten von Abload ins Leere. Darüber hinaus findet Suchen & Ersetzen auf die originalen erkannten Links statt. Das deckt z.B. reine Links ohne Vorschaubild ab.
$linkWithImgPattern = "#(\[(?:url|URL)=)[^\]]+\]\[(?:img|IMG)\]$vanillaOldImgUrl#";
$newText = preg_replace($linkWithImgPattern, "$1{$newUimgResult->directlink}][img]{$newUimgResult->thumbnail}", $text);
// Ohne Link (nur IMG Tag) reines ersetzen mit dem Direktlink
$newText = str_replace($vanillaOldImgUrl, $newUimgResult->directlink, $newText);Wichtig ist, immer mit Fehlern zu rechnen. Daher prüfe ich am Ende meiner Ersetzungen beispielsweise, ob noch abload.de im Beitragsinhalt enthalten ist. In diesem Falle beendet sich das Skript hart, weil eine händische Prüfung mit Nacharbeiten erforderlich sind.
if(str_contains('abload.de/', $newText)) {
die("Fehler - Nicht erkannte Abloadlinks vorhanden:\n$newText");
}Wie aktualisieren wir den Beitrag?
Theoretisch wäre der einfachste Weg simples Ersetzen des Beitrages. Danach noch den Zwischenspeicher leeren und fertig. Das gefiel mir nicht, weil es destruktiv und intransparent ist. Mein erster Gedanke war eine Datenbanktabelle, die den vorherigen Beitragstext zusammen mit Metadaten wie der Beitrags-ID speichert. Dann fiel mir ein: Genau das kann das Forensystem bereits. Wird ein Beitrag von regulären Nutzern nachträglich geändert, erscheint ein Hinweis und die Unterschiede lassen sich anzeigen. Dadurch ist der vorherige Inhalt gesichert.
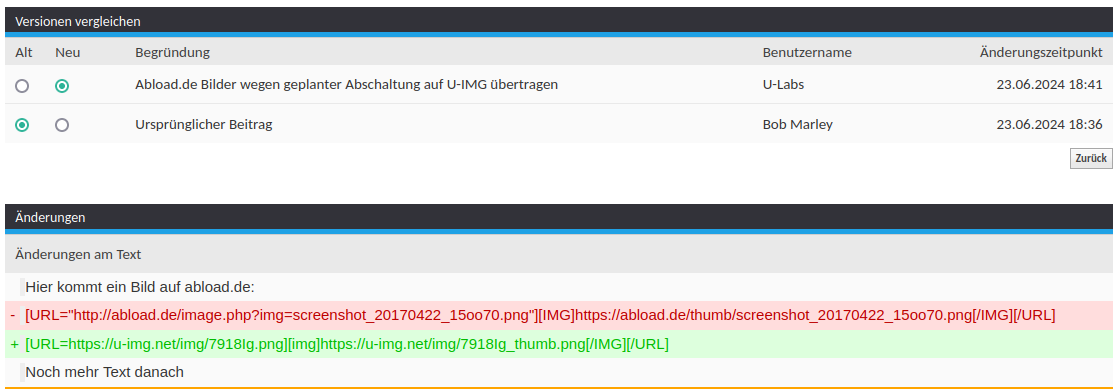
Ich erzeuge also eine neue Version mit Begründung, warum diese Änderung erfolgt. Somit ist zudem für jeden transparent, dass administrative Anpassungen erfolgt sind und warum:
Oberfläche der Migration
Ich lasse mir in einer Übersicht jeweils Titel des Themas, ID des Beitrags, jeweils Links zum Beitrag und Änderungsprotokoll sowie den Abload-Link zusammen mit zwei eingebetteten Bildern anzeigen: Das Linke ist das originale von Abload. Rechts daneben im grünen Kasten das auf U-IMG umgezogene. So kann ich auf einen Blick sehen, ob dieser Teil der Migration funktioniert hat und bei Bedarf für Stichproben in die Beiträge bzw. den Verlauf abspringen.
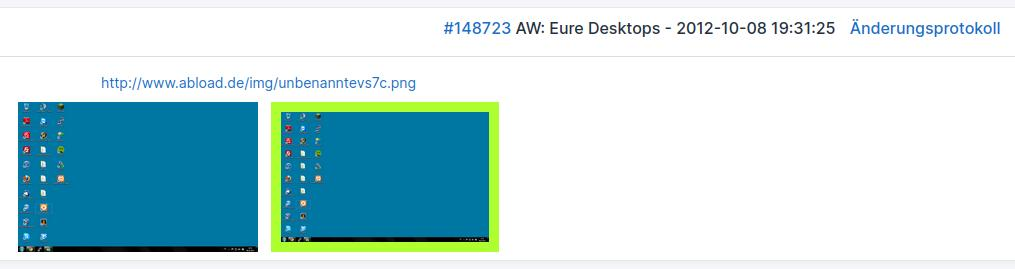
Vereinzelt kam es zu fehlerhaften Bildern. Ich habe sie händisch geprüft: Leider waren es alles Probleme seitens Abload. Die Bilder wurden entweder von deren Seite gelöscht, oder durch die Nutzer. Ein Teil konnte daher nicht umgezogen werden. Dies ist

Die wichtigsten drei Dinge bei einem derartigen Projekt
Die größte Herausforderung besteht in einer größeren Menge an Daten, bei denen wir keine 100% Klarheit über das Format haben. Und zwar auf beiden Seiten. Es gibt mehrere Möglichkeiten, wie ein Bild von Abload.de eingebettet sein kann: In voller Größe eingebettet, als Vorschaubild mit Link oder ausschließlich als Link. Der Aufbau der Links ist unterschiedlich. Alte Links sind noch mit HTTP statt HTTPS versehen, weil HTTPS vor einigen Jahren noch nicht so verbreitet war, wie heute. Selbst nach einer stichprobenartigen Analyse kann man nie sicher sein, alle Varianten gefunden zu haben.
Wichtig sind bei so etwas daher drei Dinge:
Validieren mit Positivprüfungen Man sollte so viel wie möglich Prüfen, ob die Daten dem Format entsprechen, welches man erwartet und benötigt. Andernfalls muss die Software in einem definierten Stand abbrechen. Müssen Datensätze in mehrere Tabellen eingetragen bzw. geändert werden, setze ich beispielsweise auf Transaktionen. Geht hier etwas schief, lassen sich diese Zurückrollen.
Ausführlich testen Vor allem Anfangs am besten simulieren und später zunächst kleine Datenmengen verwenden. Darauf achten, dass die Testdaten gemischt sind: Nicht nur z.B. die ältesten oder neuesten Beiträge eines Nutzers. Im schlechtesten Falle ist das ein Power-Nutzer, der alles richtig macht - im Gegensatz zu anderen. Insbesondere die ersten Tests müssen händisch überprüft werden. Auch später schadet es nicht, zumindest stichprobenartig über die Ergebnisse zu schauen. Am besten baut man entsprechende Funktionen ein, die das erleichtern.
Sichern Die Frage ist nicht, ob der NEIN?! Doch! Oh... Moment kommt, sondern wann. Manches ist nicht vorhersehbar und manchmal irrt sich der Beste. Durch vorsichtige Tests lässt sich der Schaden davon bereits begrenzen. Am besten ist es, mindestens eine funktionsfähige (!) Sicherung zu haben. Das kann eine Sicherung der Datenbank sein, die speziell vor Massenverarbeitungen unbedingt gemacht werden sollte. Versionierung ist ebenfalls nützlich, um Teildaten wiederherstellen zu können.
Was wurde erreicht?
Bei der Fertigstellung dieses Beitrages ist die Migration erfolgreich abgeschlossen: Insgesamt 2.221 Bilder wurden versucht zu migrieren, bei 174 war das leider nicht möglich. Sie wurden entweder vom Benutzer oder durch Abload gelöscht. Dies betrifft 7,8%. Rund 92,2% aller Bilder konnten damit gerettet werden.
Darunter ist beispielsweise die aufwändige Erklärung des Nutzers Nuebel zu einer Mathematik-Klausur. Eine Menge an digitaler Kunst wurde vor dem digitalen Mülleimer gerettet: One Piece Signaturen sowie diverse weitere Signaturen und Avatare eben so, wie etwa Titelbilder für diverse Spiele - Trackmania ist hier nur ein Beispiel von vielen. Auch animierte Banner von U-Hacks (so hieß U-Labs früher) wurden von den Erstellern bei Abload gehostet. Eben so wie das Bildschirmfoto dieses Assembler-Programms. Verschiedene Bilder zeigen PC-Hardware. Hier etwa ein angekokeltes IDE-Kabel, das man schon wegen des technischen Alters seit Jahren nicht mehr sieht - schon damals war das relativ alt.
Dieser Beitrag zeigt Auszüge von Knuddels aus dem Jahre 2012, kurz nachdem sie sich vom rosa Design verabschiedet hatten. Auch Anleitungen enthalten diverse Bildschirmfotos - hier etwa zur Entwicklung eines Knuddels Proxys. Oder die damals veröffentlichten Knuddels-Bots. Bei einer Programmierübung zur Berechnung des Kindergeldes zeigt auch weiterhin ein Bild den Programmablaufplan. Eben so wie die grafische Oberfläche in dieser Antwort. Wie YouTube 2012 nach einer Änderung des Designs ausgesehen haben muss, lässt dieser Beitrag erahnen. Manche betreffen sogar historische Ansichten der ersten U-Hacks Versionen. Ironischerweise hat hier jemand ein Bildschirmfoto von Abload selbst gemacht und hochgeladen. Die Liste ließe sich bei über 2.200 Bildern noch ewig fortsetzen.
Wer ebenfalls Abload direkt oder wie in diesem Falle indirekt nutzt, sollte dies in den nächsten Tagen prüfen und zeitnah migrieren. Ansonsten sind die Inhalte bald wahrscheinlich irreparabel verloren. Besonders einfach funktioniert der Export für Inhaber eines Abload-Kontos. Der Anbieter stellt Anleitungen bereit, wie man die Bilder sichert.11
Fazit: Überlasst die Zukunft eurer Daten nicht anderen!
Das Ende von Abload zeigt einmal mehr: Selbst etablierte Anbieter werden ggf. nach einiger Zeit dazu gezwungen, ihre Dienste einzustellen. Dies kann erhebliche Auswirkungen auf das freie Web haben. Erinnert sich noch wer an SchülerVZ oder Kwick? Die damals großen Netzwerke sind inzwischen verschwunden, inklusive aller Nutzerinhalte. Wer Erinnerungen aus der Jugendzeit dort hochgeladen hatte und sie nicht mehr lokal besitzt, hat seit 2021 Pech gehabt. Bei Kwick wurde der Stecker sogar unangekündigt gezogen.12 Auch Plattformen die noch nicht gestorben sind, können eure Daten verlieren: MySpace musste eingestehen, sämtliche Musik von 2003 bis 2015 verloren zu haben.13 Reddit löschte alle Chatnachrichten vor dem 30.06.2023.14
Trotz des baldigen Endes freut sich Abload.de sicher über eine Spende von euch, alle Infos dazu findet ihr auf dieser Seite. Immerhin laufen die Kosten für die Infrastruktur mindestens bis zum Ende weiter - ggf. durch Fristen noch etwas länger. Und auch die Auflösung eines Dienstes ist mit Aufwendungen sowie Kosten verbunden.
Als Konsequenz solltet ihr die Sicherheit von Daten, die euch wichtig ist, nicht anderen überlassen. Erstellt euch eine Übersicht, welche Inhalte wo gespeichert sind und worauf ihr verzichten könnt. Der Rest sollte bei euch archiviert werden. Nur so ist sichergestellt, dass geliebte Inhalte oder schöne Erinnerungen auch in ein paar Jahren noch verfügbar sind.
Quellen
- https://abload.de/blogpost.php?id=1 ↩︎
- https://abload.de/blogpost.php?id=607 ↩︎
- https://www.hosteurope.de/blog/exx-haben-soziale-netzwerke-das-web-zerstoert/ ↩︎
- https://abload.de/blogpost.php?id=625 ↩︎
- https://abload.de/blogpost.php?id=635 ↩︎
- https://abload.de/picload404.php ↩︎
- https://archive.li/https://abload.de/ ↩︎
- https://www.img.vision/handbook/what-happened-to-tinypic/ ↩︎
- https://www.php.net/manual/en/book.curl.php ↩︎
- https://stackoverflow.com/a/78658611/3276634 ↩︎
- https://abload.de/helpDownload.php?1719243422 ↩︎
- https://web.archive.org/web/20170603205725/https://www.kwick.de/ ↩︎
- https://www.heise.de/news/Datenverlust-Myspace-verliert-riesiges-Musikarchiv-4338737.html ↩︎
- https://www.heise.de/news/Reddit-Chathistorie-von-vor-2023-bei-Datenumzug-verloren-gegangen-9218302.html ↩︎