
Wer mehrere Webanwendungen per HTTP bzw. HTTPS auf dem Raspberry Pi oder jedem anderen Linux-Server betreiben möchte, wird feststellen: Jeder Port darf nur von einer Anwendung belegt werden. Genauer gesagt nur einmal pro IP-Adresse. Betreiben wir beispielsweise eine NextCloud (oder aber jeden anderen Webdienst) auf dem Standard-HTTP Port 80 und möchten zusätzlich eine weitere Anwendung wie z.B. WordPress betreiben, kann WordPress den Port nur nutzen, wenn es zusammen mit NextCloud im gleichen Webserver läuft.

In diesem Szenario wäre das möglich. Anders sieht es aber aus, wenn eine Anwendung einen anderen Webserver benötigt oder unsere Programme in Docker-Containern laufen: In diesem Falle kann Port 80 nicht verwendet werden, da er bereits belegt ist. Man müsste daher einen anderen freien Port nutzen, etwa 81. Die entsprechenden Portnummern sich zu merken und diese immer angeben zu müssen, ist unbequem und wird zudem schnell unübersichtlich.

Was ist ein Reverse Proxy?
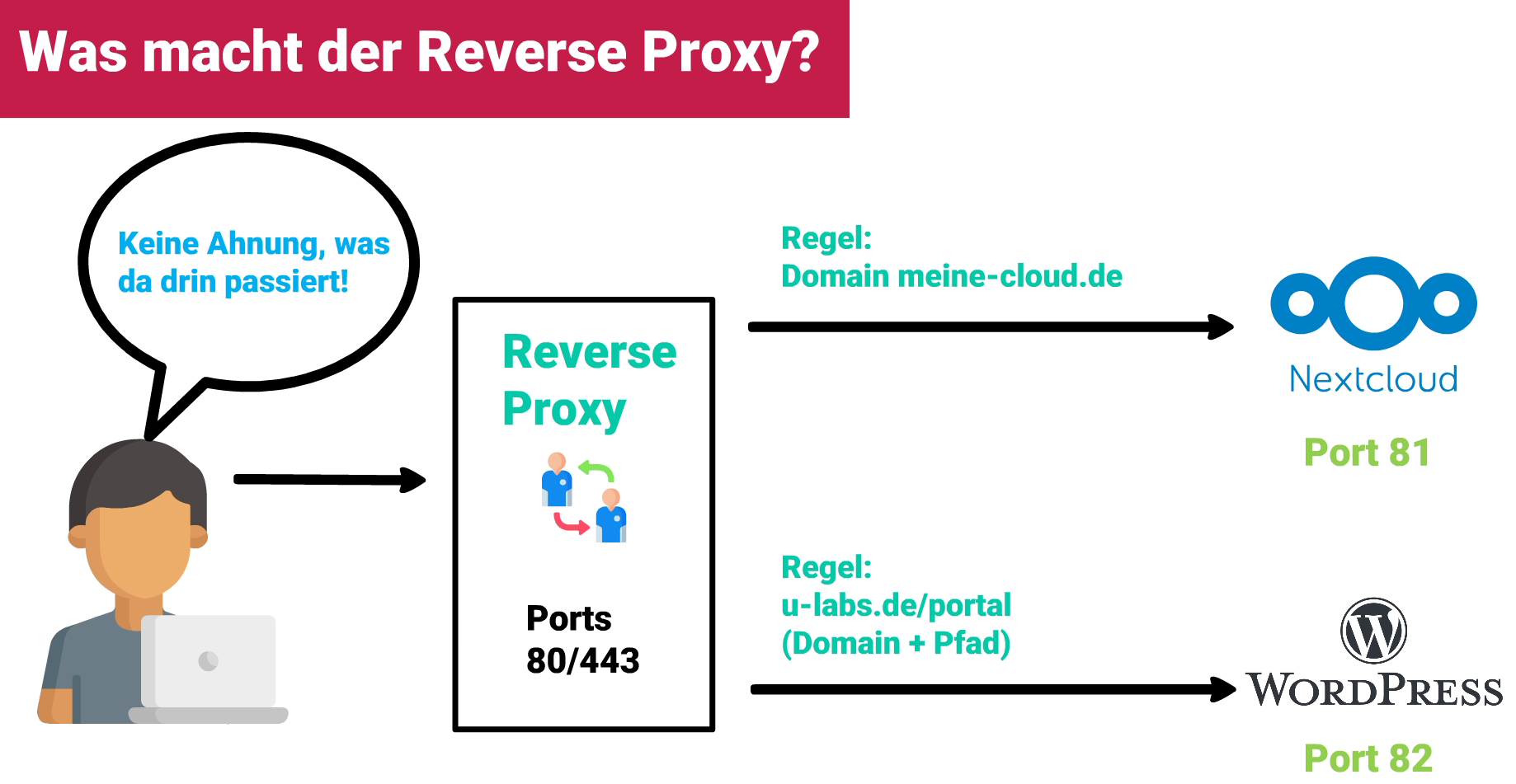
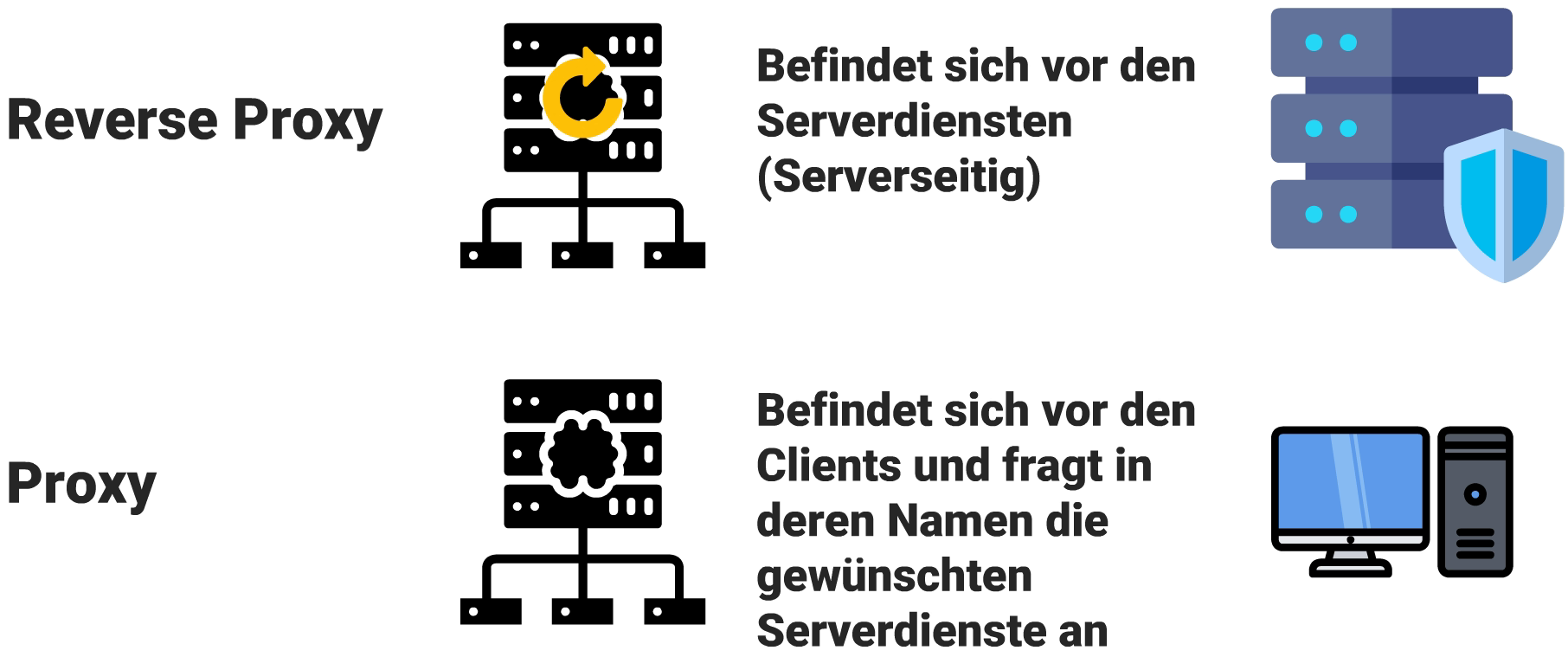
Hier kommt ein Reverse Proxy ins Spiel: Ein Proxy ist ein Stellvertreter. Wir Platzieren den Reverse Proxy auf den gewünschten Ports, hier 80. Er nimmt alle Verbindungen an und entscheidet anhand von Regeln, welche Daten er an welchen Dienst weiterleitet. Bei HTTP bieten sich Domains oder Subdomains an. Unterverzeichnisse sind auch möglich, wobei das – je nach Anwendung dahinter – Probleme bereiten kann. Die Programme hinter dem Reverse Proxy können andere Ports nutzen, etwa 81 für NextCloud und 82 für WordPress. Der Proxy-Server leitet die Daten auf die entsprechenden Ports weiter. Der Nutzer des Programmes bekommt davon nichts mit. Die Ports müssen dort auch nicht angegeben werden. Aus Sicht des Anwenders kommuniziert er direkt mit unserem Reverse Proxy auf Port 80.
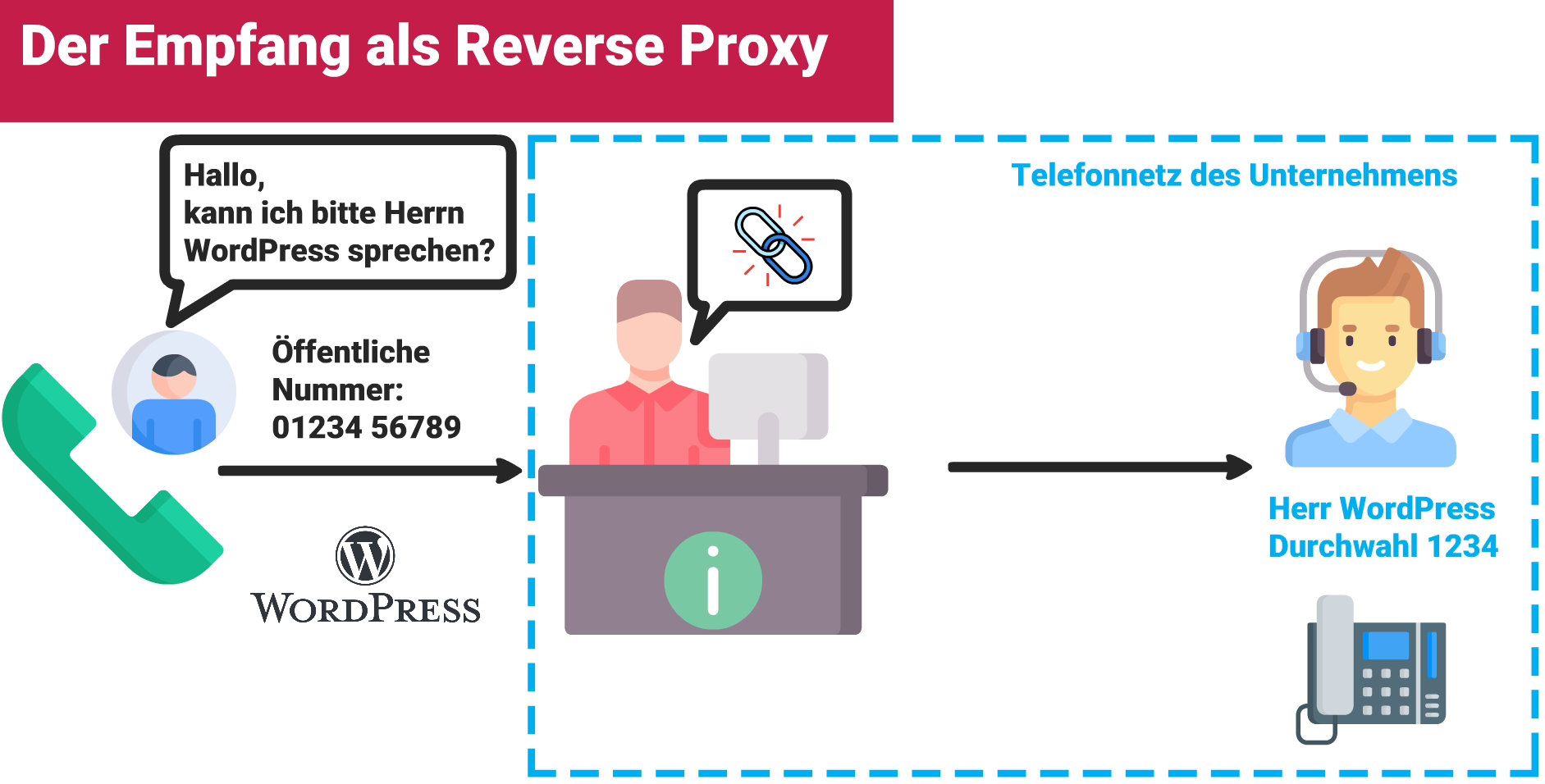
Stelle es dir ungefähr so vor, wie der Empfang eines Unternehmens: Du rufst den Empfang an und sagst, mit wem du sprechen möchtest (das wäre hier die Anwendung, wie z.B. WordPress). Anschließend wirst du direkt mit der gewünschten Person verbunden. Dass diese Person eine eigene Telefonnummer und vielleicht sogar ein anderes Telefon nutzt, merkst du nicht – dein Anruf läuft ja weiterhin auf die Telefonnummer vom Empfang. Es spielt aber auch keine Rolle: Die Telefonanlage des Unternehmens kümmert sich darum, die hier ähnlich funktioniert wie ein Reverse Proxy.
Wie grenzt sich der Reverse Proxy zu einem „normalen Proxy“ ab?
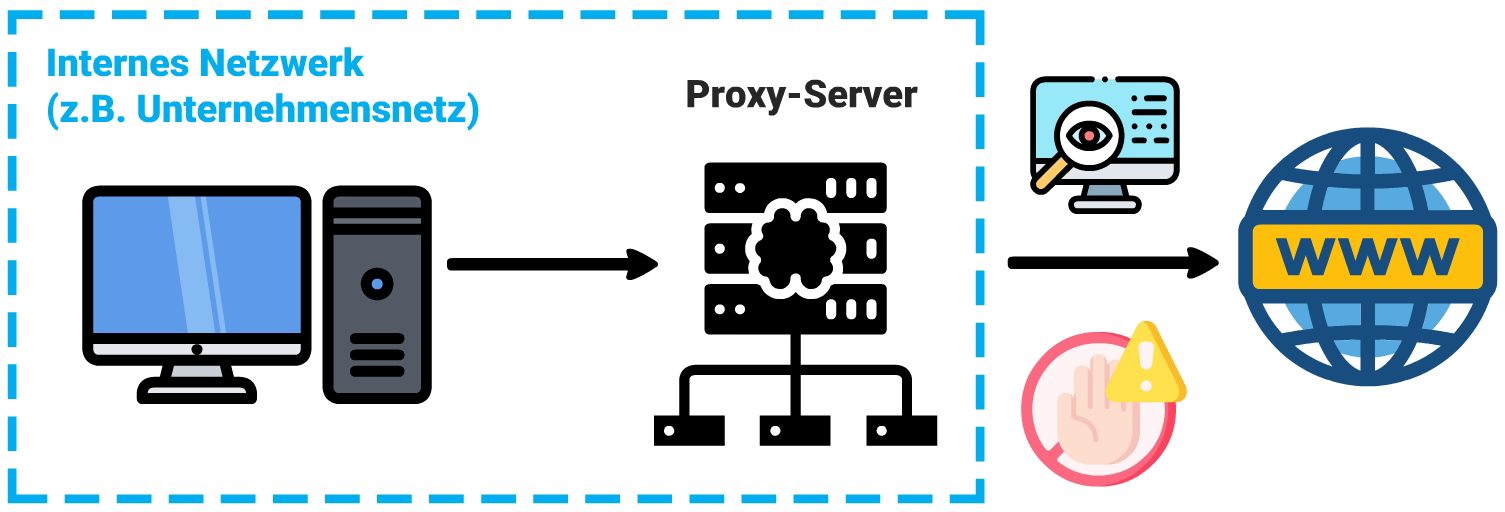
Ein typischer Proxy ermöglicht es Computern aus einem internen, geschlossenen Netzwerk heraus auf externe Dinge zuzugreifen. Dies wird z.B. im Unternehmensnetzwerken genutzt, um den Internetzugriff zu kontrollieren und ggf. auch zu überwachen. Der Client baut hier also eine Verbindung zum Proxy auf, der wiederum als Vermittler die gewünschte Ressource (z.B. eine Internetseite) anfragt und die Antwort zurück liefert.
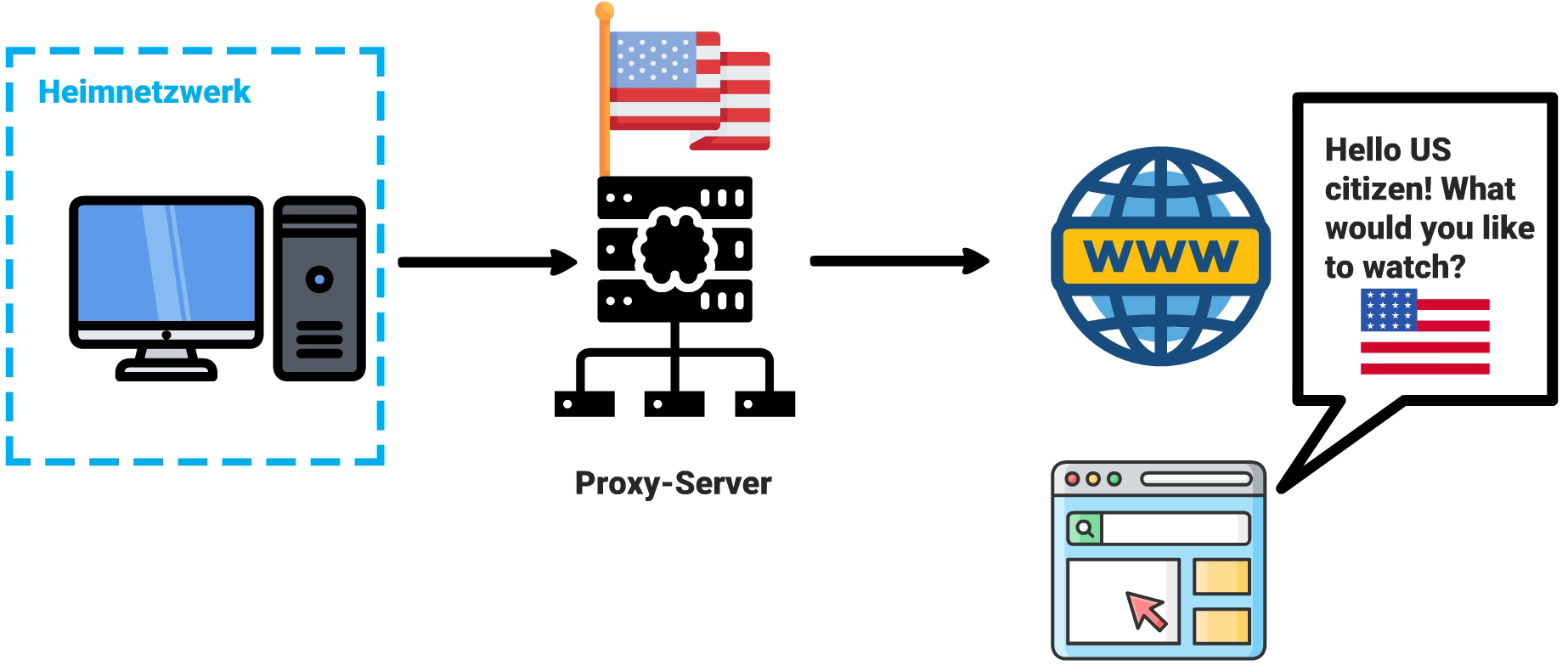
Privat können Proxy-Server genutzt werden, um ein anderes Land vorzutäuschen. Ein Proxy-Server in den USA beispielsweise gaukelt einer Internetseite vor, man wäre US-Bürger. So können Ländersperren umgangen werden, etwa bei Filmen oder Serien.
Der Reverse Proxy sitzt dagegen am anderen Ende, also nicht vor einem Client, sondern vor einem Server bzw. dessen Diensten. Ein Client fragt einen Server an und landet beim Reverse Proxy, der entsprechend an den Zieldienst vermittelt – ohne, dass der Client etwas davon mitbekommt. Daher spricht man von einem „umgekehrten Proxy“, auf Englisch Reverse Proxy.
Vorteile eines Reverse Proxys
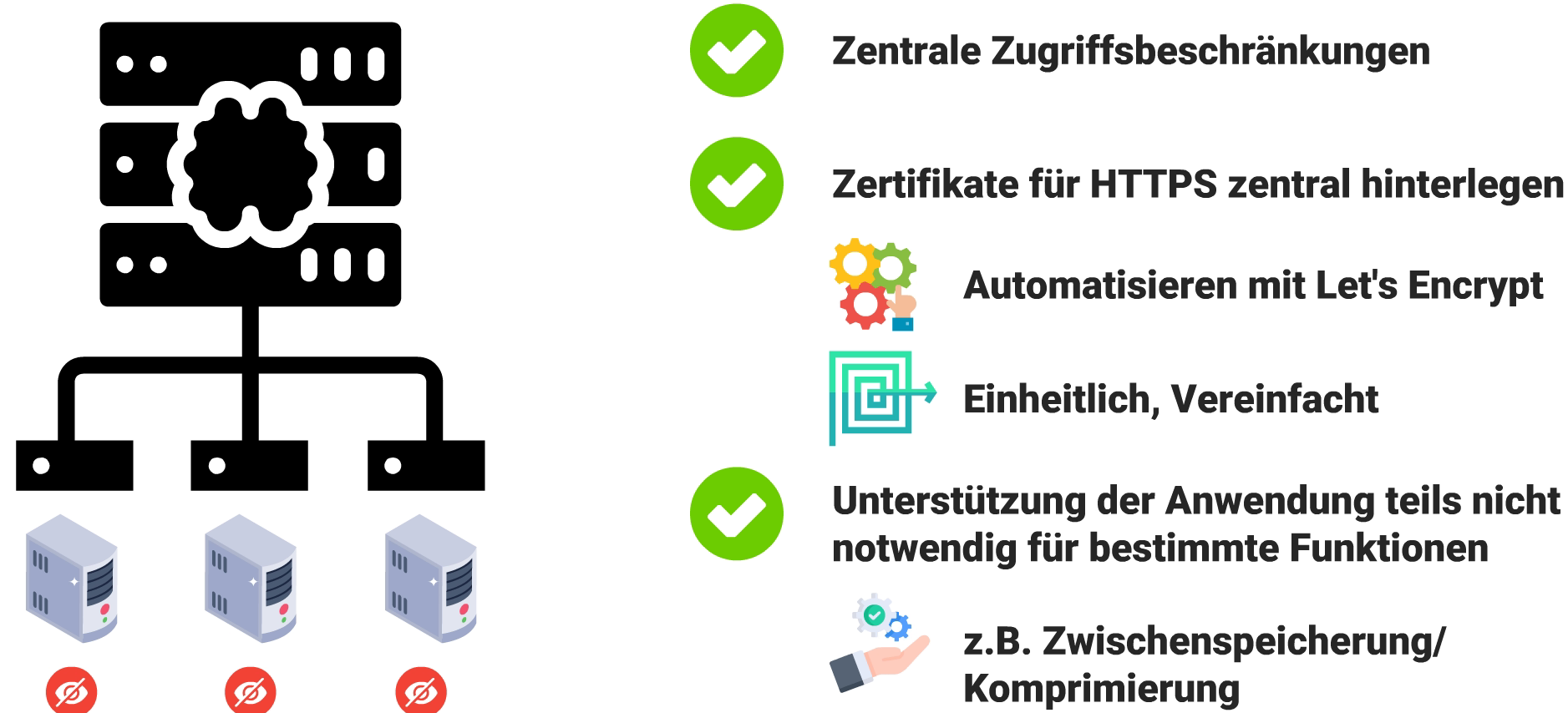
Einfach gesagt können wir also verschiedene Webserver hinter einem Reverse Proxy bereitstellen, ohne dass dies nach außen hin über z.B. mehrere Ports sichtbar ist. Aber das Konzept bietet noch weitere Vorteile: Beispielsweise lassen sich Zugriffsbeschränkungen einbauen, damit bestimmte Anwendungen nicht überall bzw. für jeden erreichbar sind. Wer HTTPS nutzen möchte, kann auf dem Reverse Proxy zentral die Zertifikate hinterlegen oder dies mit Let’s Encrypt automatisieren. So liegen die Zertifikate an einer Stelle, statt auf den einzelnen Anwendungen verstreut. Das vereinfacht die Verwaltung und man ist nicht darauf angewiesen, dass z.B. Let’s Encrypt die Anwendung unterstützt. Spätestens wenn Webdienste direkt übers Internet erreichbar werden, sollte über Transportverschlüsselung mit HTTPS nachgedacht werden.
Darüber hinaus lassen sich Inhalte zwischenspeichern oder andere Maßnahmen ergreifen, um die Leistung zu verbessern. Etwa für alle Dienste GZIP oder eine andere Komprimierung einschalten. Modernere Verfahren wie Brotli lassen sich so zentral aktivieren, auch wenn manche Anwendungen dies nicht unterstützen.
In größeren Umgebungen hat man möglicherweise mehrere Instanzen einer Anwendung. Viele Reverse Proxys unterstützen Lastverteilung, sodass man die Anfragen an mehrere Instanzen oder sogar Server aufteilen kann.
Welche Reverse Proxys gibt es?
Nahezu jeder gängige Webserver besitzt ein entsprechendes Modul, um sich wie ein Reverse Proxy zu verhalten. Beispielsweise Nginx, Apache und LiteSpeed, die verbreitetsten quelloffenen Webserver. Nginx und LiteSpeed sind auf hohe Leistung sowie einen geringen Ressourcenverbrauch optimiert. Die Unterschiede zu Apache machen sich eher auf leistungsschwachen Servern wie z.B. älteren Pis bemerkbar, oder wenn man eine gewisse Last auf das System bekommt.
Wer Docker nutzt, kann theoretisch auch einen der genannten klassischen Webserver als Reverse Proxy konfigurieren. Es gibt hierfür aber modernere Alternativen wie Traefik oder der Nginx Proxy Manager. Sie vereinfachen die Einrichtung und Verwaltung deutlich, da sie auf die Container-Welt zugeschnitten sind. Dies werde ich noch in eigenen Beiträgen genauer zeigen.
