
Die KI-Revolution ist da: Dank beeindruckender Fortschritte können Bilder mittlerweile auf einem Raspberry Pi Einplatinencomputer für weniger als 100 Euro generiert werden. Dieser Beitrag zeigt dir, wie du den Stable Diffusion Port namens OnnxStream auf einem Raspberry Pi spielend leicht installierst – dank fertigem Skript. Außerdem liefert er Hintergrundwissen über die Funktion der Komponenten sowie die wichtigsten Praxistipps, um gute Ergebnisse bei der Bildgenerierung zu erzielen. Inklusive Beispielen, was im Bereich der KI-Bildgenerierung auf einem Raspberry Pi beeindruckendes möglich ist. Alle Bilder auf dem Vorschaubild (außer Logo & Grafik rechts) wurden übrigens auf einem Raspberry Pi 5 mit dem unten folgenden Software-Stack installiert.
Was brauche ich?
Zu empfehlen ist ein Raspberry Pi 5 mit aktiver Kühlung – ansonsten wird er sich wahrscheinlich während der Generierung drosseln. Theoretisch sind auch deutlich ältere & damit schwächere Modelle möglich. Allerdings ist dort alles deutlich langsamer – sowohl die Installation, als auch das Generieren von Bildern. Mit jeweils einem Schritt ist ein Bild auf einem Raspberry Pi 5 bereits nach ca. 3:16 Minuten erstellt, während ein Raspberry Pi 4 ganze 13:54 Minuten auf sich warten lässt. Das Hinzufügen eines Schritts verzögert den Prozess auf dem Raspberry Pi 5 um jeweils etwa eine Minute:
- 1 Schritt: 3:16 Minuten
- 2 Schritte: 4:18 Minuten
- 3 Schritte: 5:23 Minuten
Da OnnxStream darauf ausgelegt ist, mit nur 512 MB Arbeitsspeicher (!) des Raspberry Pi Zero 2 zu laufen, kann es selbst auf derart leistungsschwachen Einplatinencomputern genutzt werden. Allerdings muss man dort mit knapp einer halben Stunde pro Bild (1 Schritt) rechnen. Zum Vergleich: Das „normale“ Stable Diffusion (auf dem OnnxStream basiert) empfiehlt mindestens 8 GB Arbeitsspeicher. Durch verschiedene Optimierungen (welche die Generierung etwas verlangsamen) reichen 4 GB.
In jedem Falle benötigst du reichlich freien Speicherplatz: Die Installation mit nur dem SDXL Turbo Unet Modell (siehe Komponenten unten) belegt bereits ca. 18 GB. Fast der gesamte Speicherplatz entfällt dabei auf das Modell. Falls du weitere installieren möchtest, ist daher deutlich mehr Speicherkapazität nötig. Dazu kommt das Raspberry Pi OS, welches im Vergleich dazu mit wenigen Gigabytes sehr klein wirkt. Mindestens 32 GB sollte die Speicherkarte für ein Modell groß sein.
Darüber hinaus müssen all diese Daten auch aus dem Internet geladen werden. Eine schnelle Internetanbindung ist daher von Vorteil. Ansonsten wirst du längere Zeit warten müssen – hier macht es ggf. Sinn, die Installation per Skript zu starten.

Die Komponenten
Die Installation besteht aus insgesamt drei Komponenten, welche wir herunterladen und teilweise kompilieren müssen. Zuvor werfen wir darauf einen kurzen Blick, damit dir klar wird, welche Bedeutung sie für unseren Bildgenerator haben.
XNNPACK ist eine von Google entwickelte Bibliothek, die grundlegende (Low Level) Funktionen für Frameworks aus dem Bereich Maschinellen Lernens bietet.1 Sie soll deren Leistung durch starke Optimierung verbessern. Da XNNPACK nicht nur X86, sondern auch für ARM und sogar RISC-V unterstützt, bietet es sich als Grundlage für den Raspberry Pi an.
OnnxStream hat es mithilfe von XNNPACK geschafft, Stable Diffusion derart extrem zu optimieren, damit es selbst auf einem vergleichsweise sehr schwachen Raspberry Pi Zero 2 läuft.2 Stable Diffusion ist ein quelloffener Deep-Learning Text-zu-Bild-Generator. Wie man ihn installiert und nutzt, habe ich bereits in diesem Artikel beschrieben. Allerdings wurde dafür bislang ein X86 System mit mindestens 4 GB dedizierten Grafikspeicher benötigt, empfohlen sind 8 GB. Dies ist nicht zu verwechseln mit dem Arbeitsspeicher des Raspberry Pi.
SDXL Turbo Unet model for OnnxStream liefert als Modell die notwendige Datenbasis, um Bilder zu generieren. Wie bei anderen Bildgeneratoren ist das Modell austauschbar: OnnxStream unterstützt darüber hinaus Stable Diffusion 1.5 und Stable Diffusion XL 1.0.
Vorbereitung
Um den Code der Projekte zu kompilieren, benötigen wir einige Werkzeuge, die nicht standardmäßig auf dem Raspberry Pi OS installiert sind. Darunter CMake für C/C++ und Git-LFS (Large File System), um die großen KI/ML-Modelle verarbeiten zu können.
sudo apt install cmake git-lfsInstallation
XNNPACK ist eine Abhängigkeit von OnnxStream. Wir müssen daher zunächst XNNPACK kompilieren, um damit anschließend OnnxStream ebenfalls kompilieren zu können. Schlussendlich lässt sich OnnxStream mit dem heruntergeladenen Modell starten. Für all diese Komponenten solltest du zunächst einen Ordner anlegen. Da wir dessen Pfad an einigen Stellen referenzieren, macht es Sinn, ihn in einer Variable zu speichern.
export baseDir=/home/u-labs/sd-rpi
mkdir $baseDir
cd $baseDirNun klonen wir das XNNPACK-Repository und müssen jedoch einen bestimmten Branch auschecken, da diese Bibliothek eigenständig entwickelt wird. Änderungen, die nicht abwärtskompatibel sind und noch nicht in OnnxStream eingepflegt wurden, könnten daher ansonsten zu Problemen führen.
git clone https://github.com/google/XNNPACK.git
cd XNNPACK
git checkout 579de32260742a24166ecd13213d2e60af862675
mkdir build
cd build
cmake -DXNNPACK_BUILD_TESTS=OFF -DXNNPACK_BUILD_BENCHMARKS=OFF ..
cmake --build . --config ReleaseZurück im Basis-Verzeichnis laden wir das Modell – wir nutzen hier SDXL Turbo. Hier müssen wir nichts bauen, allerdings einige Gigabyte an Daten aus dem Internet laden:
cd $baseDir
git lfs install
git clone --depth=1 https://huggingface.co/AeroX2/stable-diffusion-xl-turbo-1.0-onnxstreamSchlussendlich erfolgt das klonen & bauen von OnnxStream:
cd $baseDir
git clone https://github.com/vitoplantamura/OnnxStream.git
cd OnnxStream/src
mkdir build
cd build
cmake -DMAX_SPEED=ON -DXNNPACK_DIR=$baseDir/XNNPACK ..
cmake --build . --config ReleaseNun können wir die erstellte Binärdatei namens sd nutzen, um Bilder zu generieren. Dafür wird ihm der Pfad zum Model übergeben, das zuvor heruntergeladen wurde. Der Promt gibt an, welches Bild generiert werden soll. Weitere Parameter sind teilweise in Abhängigkeit vom Modell verfügbar – etwa ein negativer Promt, um bestimmte Beschreibungen auszuschließen, die man auf keinen Fall haben möchte (von SDXL Turbo nicht unterstützt).
cd $baseDir/OnnxStream/src/build/
time ./sd --turbo --rpi --models-path $baseDir/stable-diffusion-xl-turbo-1.0-onnxstream --prompt "An astronaut riding a horse on Mars" --steps 1 --output astronaut.pngFür die bequeme Installation habe ich ein Skript geschrieben, das alle Komponenten nacheinander installiert:
#!/bin/bash
set -e
export baseDir=/home/u-labs/onxx-stream
mkdir $baseDir
cd $baseDir
command -v cmake >/dev/null || sudo apt-get install -y cmake
command -v git-lfs >/dev/null || sudo apt-get install -y git-lfs
git clone https://github.com/google/XNNPACK.git
cd XNNPACK
git checkout 579de32260742a24166ecd13213d2e60af862675
mkdir build
cd build
cmake -DXNNPACK_BUILD_TESTS=OFF -DXNNPACK_BUILD_BENCHMARKS=OFF ..
cmake --build . --config Release
cd $baseDir
git lfs install
git clone --depth=1 https://huggingface.co/AeroX2/stable-diffusion-xl-turbo-1.0-onnxstream
cd $baseDir
git clone https://github.com/vitoplantamura/OnnxStream.git
cd OnnxStream/src
mkdir build
cd build
cmake -DMAX_SPEED=ON -DXNNPACK_DIR=$baseDir/XNNPACK ..
cmake --build . --config Release
# Aufruf
#cd $baseDir/OnnxStream/src/build/
#time $baseDir/sd --turbo --rpi --models-path $baseDir/stable-diffusion-xl-turbo-1.0-onnxstream --prompt "An astronaut riding a horse on Mars" --steps 1 --output astronaut.pngDas Wichtigste zum Experimentieren: Der „seed“
Ein generelles Problem bei KI/ML ist Reproduzierbarkeit. Wer ChatGPT & co. bereits ausprobiert hat, wird wissen: Dreimal die gleiche Frage (v.a. in einer neuen Instanz) zu stellen, wird selten dreimal zur gleichen Antwort führen. Zumindest bei der Bildgenerierung gibt es mit dem Seed eine Nummer, die das ermöglichen soll. Das ist vor allem zum Experimentieren mit anderen Parametern hilfreich.3 Ansonsten ist unklar, ob eine Veränderung aufgrund eines Parameters entstanden ist, oder eher zufällig, wie folgendes Beispiel zeigt. Der Seed ist eine frei wählbare Nummer. Es spielt keine Rolle, welchen Wert man nimmt – wichtig ist nur, dass er zur Reproduzierbarkeit identisch bleibt.
Ich habe jeweils den Promt „fairy tale landscape hq high resolution“ verwendet und lediglich die Schritte erhöht: Bild 1 wurde mit --steps 1 generiert, dann --steps 2 und --steps 3. Wie zu erwarten ist das Bild in drei Schritten detaillierter und farbenfroher, doch es hat sich auch inhaltlich deutlich verändert. Beispielsweise der Baum links, der kleine Wasserfall, weniger Türme usw.

Nutzen wir den gleichen Promt mit einem Seed (z.B. --seed 22849), sieht das Ergebnis anders aus. Detailveränderungen kann es natürlich auch hier geben, da durch zusätzliche Schritte nicht nur vorhandenes feiner, sondern ggf. zudem erweitert wird. Die Unterschiede fallen hier jedoch geringer und reproduzierbarer aus. Das kann an anderer Stelle ebenfalls nützlich sein – etwa, um mit negativen Promts zu experimentieren (sofern vom Modell unterstützt). Oder um Details zu verändern: Wenn man mit dem generierten Motiv zufrieden ist, aber beispielsweise das Gesicht einer Person nur lächeln statt lachen soll.
Im Folgenden Beispiel habe ich den identischem Promt mit Seed 22849 verwendet und wieder mit Schritten von 1 bis 3 generieren lassen. Das Motiv sieht anders aus als die Vorherigen, da ein zufällig generierter Seed zum Einsatz kommt, wenn man keinen explizit angibt. Da wir einen angegeben habe, bleibt das Motiv im Kern gleich. Lediglich Details kommen hinzu, wie etwa die Brücke links, welche erst ab 3 Schritten als solche erkennbar wird.

Was hat es mit den Schritten (–steps) auf sich?
Künstlich generierte Bilder werden oft in mehreren Schritten generiert: Der Generationsprozess auf Basis des Text-Promts wiederholt sich und ergeben zusammen das fertige Bild. Als Faustformel kann man sagen: Je mehr Schichten, um so detaillierter und hochqualitativer wird das Ergebnis. Vereinzelt verändert sich das Bild, weil Details hinzugefügt oder verlagert werden. Aber es wird sich nicht komplett um 180 Grad drehen.
Bereits in nur einem Schritt generiert OnnxStream ansehnliche Ergebnisse, die oft etwas verwischt nach Ölzeichnungen aussehen. Das variiert je nach eingesetztem Promt. Ab drei Schritten erhöht sich die Qualität & Detailtiefe deutlich sichtbar, wie folgendes Beispiel zeigt. Alle wurden mit jeweils 1, 2 und 3 Schritten (von links nach rechts) generiert, sofern nicht anders angegeben.
Unendlich steigern lässt sich dies nicht: Da mit jedem Schritt zusätzliche Informationen entstehen, wirkt das Bild irgendwann übersättigt.4 Dies demonstrieren folgende Beispiele, welche mit dem Promt „A cinematic shot of a raccoon in the water of the wood“ und gleichem Seed (siehe nächster Abschnitt) generiert wurden: Im ersten Bild sind 5 Schritte zu sehen, es wirkt natürlich. Das Zweite zeigt 7 Schritte und ist etwas detaillierter, wirkt im direkten Vergleich bereits leicht übersättigt. Spätestens das letzte Bild wirkt mit seinen 10 Schritten unnatürlich.

Das muss nicht zwingend schlecht sein: Es gibt Anwendungsfälle, bei denen genau das erwünscht ist. Außerdem kommt es zudem auf das Motiv (und damit den eingegebenen Promt) an, wie sich ein Bild mit steigender Anzahl an Schritten entwickelt. Bei Comic-Stil beispielsweise werden die Motive detaillierter, heller und kräftiger, wie unser zuvor bereits eingesetzter Promt „fairy tale landscape hq high resolution“ (wieder mit gleichem Seed) zeigt. Hier wurde mit 4, 6 und 8 Schritten generiert. Ab Schritt 4 sind beispielsweise die Konturen der Blumen deutlich zu erkennen und die Brücke hat ein ebenfalls detailliert erkennbaren Zaun erhalten. Vereinzelt können auch mal kleinere Details verschwinden: Die Vögel am Horizont sind im letzten Bild nicht mehr da und auch der vordere Weg hat seine sichtbaren Konturen verloren.

Man sollte sich darüber im klaren sein, um es gezielt für optimale Ergebnisse einsetzen zu können. Für alltägliche Bilder ist ein Bereich von 3-6 oft sinnvoll. Dieser generiert in meinen Tests oft qualitativ ansehnliche, farbenfrohe Bilder. Für Comicartige Darstellungen können höhere Werte zu mehr Sättigung führen.
Eine kleine Umgebung für Experimente
Zum experimentieren habe ich mir für diesen Artikel eine minimalistische Testumgebung eingerichtet: Sie besteht aus einem Skript, dass zu verschiedenen Promts Bilder mit dem gleichen Seed in jeweils 1-8 Schritten generiert. So kann ich mehrere Promts angeben und während der länger andauernden Generierung etwas anderes machen. Zu beachten ist, dass euer angemeldeter Nutzer (hier u-labs) Rechte auf /var/www/html benötigt, um dort Bilder ablegen zu können.
sudo chown $USER -R /var/www/htmlDas Skript zur Generierung legt den Zielordner an, sofern die Rechte dafür vorhanden sind. Dies ist wichtig, weil OnxxStream noch keine Prüfung durchführt und auch keine Fehlermeldungen anzeigt, wenn der Zielpfad nicht existiert.
#!/bin/bash
target=/var/www/html/img
baseDir=/home/u-labs/sd-rpi
endStep=8
promts=(
"Penguin with lightsaber cyberpunk 2077 environment"
"Penguin with lightsaber cyberpunk 2077 style"
"Dagobert duck from the ltb comics in his money storage"
)
mkdir -p $target
startImgId=$(find $target -type f -name '*.png' -printf "%f\n" | sort -r | grep -E "([0-9]{1,})\\-steps[0-9]{1,}" | head -1 | awk -F'-' '{print $1}')
if [[ -z "$startImgId" ]]; then
echo "Keine zum Namensschema passenden Bilder gefunden, setze erste Id auf 1"
startImgId=1
else
nextImgId=$(expr $startImgId + 1)
echo "$startImgId war die Id des letzten Bildes in $target, fahre mit $nextImgId fort"
startImgId=$nextImgId
fi
for i in "${!promts[@]}"; do
realId=$(expr $i + $startImgId)
promt=${promts[$i]}
seed=$((1000 + RANDOM % 100000))
echo "[$realId] Promt: '$promt' - Steps: $i Seed: $seed"
for step in $(seq $endStep); do
time $baseDir/OnnxStream/src/build/sd --turbo --models-path $baseDir/stable-diffusion-xl-turbo-1.0-onnxstream --prompt "$promt" --steps $step --seed $seed --output $target/$realId-steps$step.png
done
done- $target ist der Ziel-Pfad, in den in den die generierten Bilder abgelegt werden. Dieser muss existieren, also zuvor mit
mkdiranlegen. - $baseDir entspricht unserem Arbeitsverzeichnis aus dem vorherigen Skript – hier liegt OnnxStream zusammen mit seinen Abhängigkeiten.
- $endStep gibt an, wie viele Schritte (angefangen von 1) jeweils generiert werden sollen. 8 bedeutet, das Skript generiert für jeden Promt jeweils ein Bild in einem Schritt, zwei Schritten, drei Schritten usw, bis die hier angegebene Zahl erreicht wurde. Dafür kommt ein zufällig pro Id generierter Seed zum Einsatz, um möglichst reproduzierbare Bilder zu erhalten.
- $promts enthält die gewünschten Zeichenketten als Array, zu denen Bilder generiert werden sollen. Beachte, dass viele Modelle entweder nur Englisch verstehen, oder zumindest in dieser Sprache am besten funktionieren.
Anschließend lassen sich diese mit einer extrem minimalistischen Weboberfläche einsehen: Als einfache Grundlage habe ich Apache mit PHP installiert. Ein Skript listet alle Bilder darin auf und zeigt sie verkleinert an, um einen Überblick zu erhalten. Grobe Unterschiede zu den verschiedenen Schritten lassen sich damit erkennen. Zusätzlich ist das originale Bild verlinkt, um es bei Bedarf in voller Auflösung öffnen zu können. Voraussetzung ist dafür die Einhaltung des Namensschemas: Jedes Bild erhält eine fortlaufende Nummer (z.B. 3) und wird nach dem Schema ${nummer}-steps${step}.png benannt. Beispielsweise 3-steps2.png, dies steht für Bild Nr. 3, welches in 2 Schritten generiert wurde.
$ cat /var/www/html/index.php
<?php
$files = glob('img/*.png');
usort($files, function($a, $b) {
return filemtime($b) - filemtime($a);
});
$fileGroups = array();
foreach($files as $file) {
if(preg_match("/([0-9]{1,})\\-steps[0-9]{1,}/", $file, $matches)) {
$imgId = (int)$matches[1];
$fileGroups[$imgId][] = $file;
}
}
?>
<style>
* { font-family: ui-sans-serif,system-ui,Segoe UI,Roboto,Ubuntu,Cantarell,Noto Sans,sans-serif,BlinkMacSystemFont,Helvetica Neue,Arial; }
</style>
<?php foreach($files as $file): ?>
<a href="<?=$file?>" target="_blank">
<img src="<?=$file?>" style="height:200px" />
</a>
<?php endforeach; ?>
<h2>Vergleich nach Seed-Gruppen</h2>
<?php foreach($fileGroups as $imgId => $files): ?>
<h3><?=$imgId?></h3>
<?php foreach($files as $file): ?>
<a href="<?=$file?>" target="_blank">
<img src="<?=$file?>" style="height:400px" />
</a>
<?php endforeach; ?>
<?php endforeach; ?>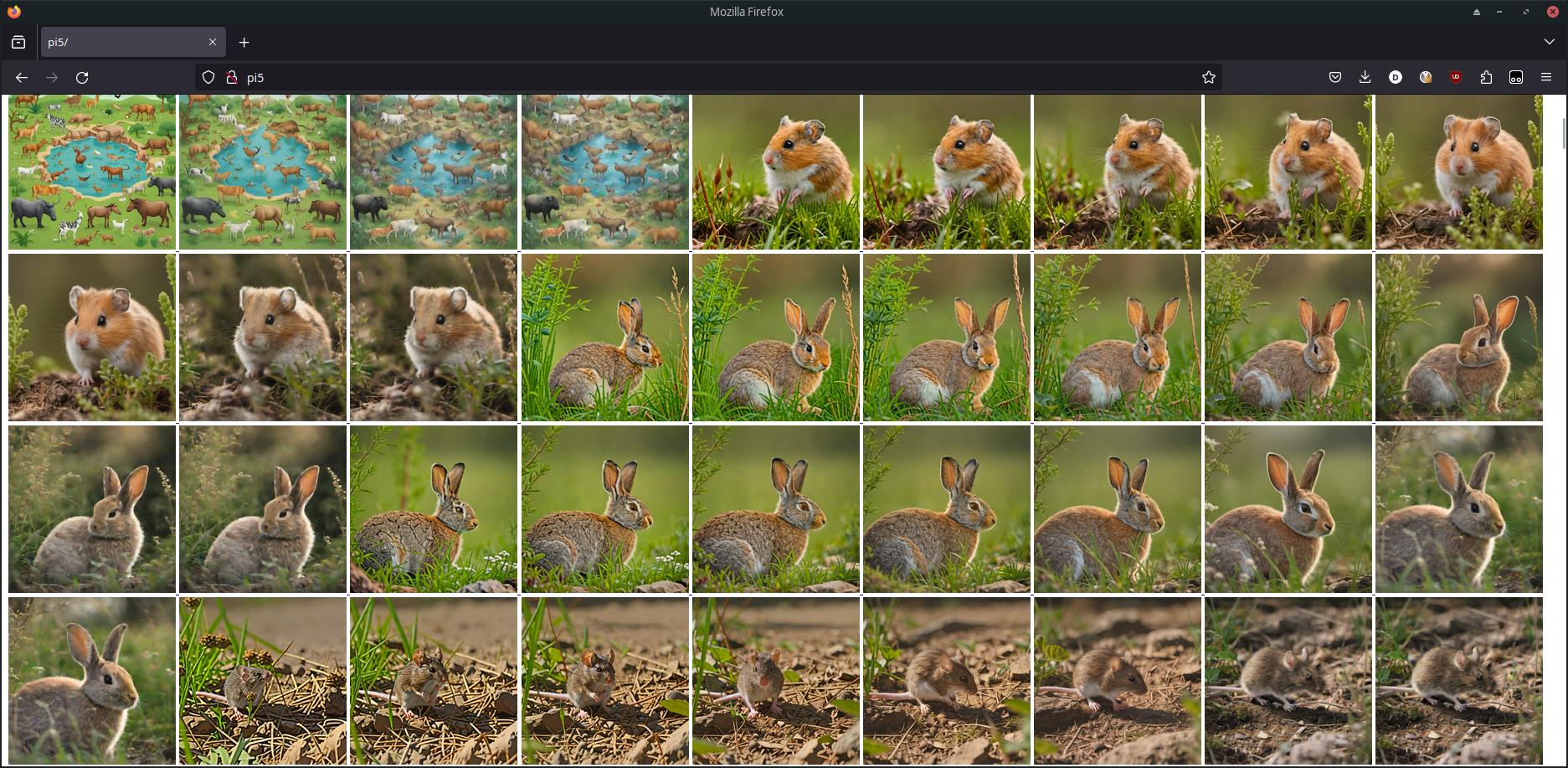
Anhand dieser Benennung generiert das Skript weiter unten Gruppen zu den jeweiligen Bildnummern, in denen sie größer dargestellt werden. So lassen sich die Bilder in verschiedenen Schritten miteinander vergleichen. Hier sehen wir etwa 8 Schritte (links oben) bis 1 Schritt (rechts unten).

Nun könnt ihr im Batch-Skript eine beliebige Anzahl an Promts im Array $promts angeben und anschließend das Skript starten:
$ cd ~/sd-rpi/OnnxStream/src/build
$ time bash batch-generate.shEs wird euch die Bilder mit der gewünschten Anzahl maximaler Schritte generieren. Nach wenigen Minuten sollte in der Mini-Weboberfläche das Erste sichtbar sein. Während die Generierung läuft, kann man etwas anderes machen – das Skript fährt automatisch mit den restlichen Promts/Schritten fort.
Kurzer Exkurs Promts schreiben
Gerade Bilder können durch einen bestimmte Art ganz anders wirken. Es macht daher Sinn, damit zu beginnen:
- Möchte ich beispielsweise eine Fotografie (Photography) oder filmische Aufnahme (Cinematic shot)?
- Eine 3D-Grafik (3D Graphics)?
- Eine Zeichnung (Drawing) oder ein Gemälde (Painting)?
Man kann auch einen bestimmten Stil angeben: Abstrakte Kunst, im Stil von XY und so weiter. Teilweise kann „high quality“ oder „hq“ für eine bessere Qualität helfen. Als nächstes sollte man möglichst präzise beschreiben, was man auf dem Bild sehen möchte. Sehr allgemeine Formulierungen wie „A dog“ können möglicherweise als Inspiration interessant sein – manch einer möchte sich vielleicht sogar überraschen lassen. Liefern aber wahrscheinlich etwas anderes, als sich dabei im Kopf gedacht wurde. Besser wäre beispielsweise „A large dog with black fur and green eyes in a meadow of flowers in the sunshine“.
Sollte das Ergebnis noch immer nicht den Vorstellungen entsprechen, muss der Promt weiter verfeinert werden: Gefällt einem etwa der Gesichtsausdruck einer Person nicht, gibt man diesen an. Soll die Tageszeit anders sein, schreibt man in den Promt, dass es z.B. Nacht sein soll. Gerade Einsteiger werden erst etwas experimentieren müssen. Allerdings ist das Schreiben von Promts kein Hexenwerk – nach relativ kurzer Zeit lassen sich damit gute Ergebnisse erzielen.
Weitere Beispiele
Während der Erstellung dieses Beitrages habe ich einige Motive (über 40) und zum Vergleichen der Schritte noch mehr einzelne Bilder generiert. Zur Inspiration und als erste Einschätzung, was man erwarten kann, findet ihr im folgenden Abschnitt einen Auszug daraus – inklusive der Promts, womit sie generiert wurden. Für Bilder mit mehreren Schritten habe ich immer einen einzigartigen Seed pro Motiv verwendet.
„A cinematic shot of a baby raccoon wearing an intricate italian priest robe.“ (4, 3 und 2 Schritte, #14)

„Cinematic shot of a cute cat in the nature“ (7, 5 und 3 Schritte, #26)

„Cinematic shot of a rabbit in the nature“ (7, 5 und 3 Schritte, #28)

„Cinematic shot of a bunny in the nature“ (6, 4 und 2 Schritte, #29)

„Cinematic shot of a hamster in the nature“ (8, 5 und 4 Schritte, #30)

„Fantasy world with multiple animals“ (8, 5 und 4 Schritte, #31)

„Unicorn on rainbow“ (8, 3 und 1 Schritte, #32)

Fazit
„Künstliche Intelligenz“ (die in Wirklichkeit meist eher maschinelles Lernen ist5) entwickelt sich in einem rasanten Tempo weiter. Anfang 2024 sind wir bereits so weit, dass ein Raspberry Pi 5 für unter 100€ in wenigen Minuten beeindruckende Bilder generieren kann. Und zwar nicht bloß über einen proprietären Drittanbieter-Clouddienst – sondern dank quelloffener Software völlig kostenlos ohne Einschränkungen.
Hier zeigt sich auch, dass Open Source den kommerziellen Unternehmen dicht auf den Fersen ist. Google sieht daher zu Recht nicht OpenAI/ChatGPT als größte Konkurrenz – sondern quelloffene KI-Software.6 Sie steckt bereits in vielen Anwendungen und ist längst im Bereich KI/ML aktiv. Es wird spannend bleiben, wie sich diese Branche in den nächsten Jahren entwickelt.
Quellen
- https://github.com/google/XNNPACK ↩︎
- https://github.com/vitoplantamura/OnnxStream ↩︎
- https://getimg.ai/guides/guide-to-seed-parameter-in-stable-diffusion ↩︎
- https://getimg.ai/guides/interactive-guide-to-stable-diffusion-steps-parameter ↩︎
- https://www.adtriba.com/de/blog/der-hype-um-ki ↩︎
- https://futurezone.at/b2b/internes-google-dokument-leak-keine-chance-gegen-open-source-ki-kuenstliche-intelligenz/402437466 ↩︎